-
I'm going to be talking the tempering of steel today. I'm sure we've all bent a piece of metal back and forth until it breaks. Working a metal by bending it, compressing it, or streching it all cause stresses to accumulate in the metal. These stresses result in work hardening. Contiuned work hardening makes the metal brittle and results in cracking, which is obviously undesirable, and what you have seen bending a piece of metal back and forth until it breaks. (30s)
-
So, let's say we're a manufacturer, and we have a roll of steel that is raw stock and nominally 1/4 inch thick. But, as a manufacturer, we must work it to thin it to 1/4" or 1/8th" to match sales specification. This will work harden it thoroughly, making it stiff, brittle, and difficult to cut or trim to final size. Annealing a steel by heating it to a few hundred, or even several hundred degrees Celcius, will reverse the work hardeneing, softening the metal again so that more work can be done easily and without permenant damage like cracking. Tempering, which I will be modeeling, is an almost identical process, but where annealing aims to make the steel as soft as possible, for continued working, tempering is done with a final target hardness mind. This final hardness is important because it's can be tested non-destructively and indicates other properties like toughness and strength. (1:20)
-
The dataset I'll be working with is from kaggle and has about 1500 rows. It was provided to the public by the company Raiipa, a metalurgical engineer consulting firm currently focusing on AI applications. The data is pulled from 3 scientific reviews, dating from 1945 to 2010. I chose to use this dataset to build an engineering tool that would allow the prediction of tempering conditions, time and temperature, needed to reach a target hardness for a given steel. To this end, there was substaintal data processing necessary; all the regular scaling and encoding problems, but I also suspected my dataset may be too limited in information to make the kind of predictions I was asking of it. So, I scraped additional mechanical properties data from the AZO Materials and Make It From websites, before joining them with the Raiipa dataset. (2:10)
-
This resulted in two things. First, discovering that some of the older steels were not made to a standard I could identify and therefore had to be thrown out or else I would introduce many nulls to the dataset. This brought me from 1500 rows to 1300 rows. Second, it introduced more multicollinearity than was already present. I know that the alloying elements of the steels greatly effect the mechanical properties, and that the certain alloying elements are added in ratios to improve certain groups of mechanical properties. The multicollinearity can be seen espectially in Molybdinum-Nickel (col Mo, Ni) and Vanadium-strength (Column V) correlations. As a result I made the decision to do a primary component analysis as well. As you can see I went from a fair amount of multicollinearity, to absolutely none, as expected of PCA. (3:10)
-
Getting back to the models, in order to predict the tempering process I built a multi-output multi-label classification model. I targetted labelling the tempering temperature and tempering time dimensions. I decided to bin both my classification targets to drive up the support factor for my labels, as there was some very low support labels present. Pictured is the post-binning of the tempering temperature target dimension far-left, and the pre- and post- binning treatment of the tempering time target dimension. After the treatments, as you can see on the far left and far right, the support balance is pretty good, though temperature target has some moderatly low support values. But this isn't so unbalanced it could not be worked with. However, this is the first real hint I had that my dataset may be insufficent for this classification problem. I went down to only 5 bins for the time target, 5 bins that cover 5 minutes to 32 hours of tempering. But i had to do this binning as I did not have the data to support a more granular classifcaitons. (4:15)
-
I proceeded onwards and attemped numerous classifier models, but settled on Extra Trees Classifer as my baseline. We can see clearly that it hugely overfits the training data, with high accuricies on the training set and very low accuracies on the testing set. I also saw this same degree of overfitting in the other drop in models I attempted. Naively, I went ahead and built classification Neural networks models as well, but they suffered the same issues, albiet with less training accuracy. One the right you casn see the two extremes of neural networks I attempted, the largest deep network, to the smallest shallow network on the right. Clearly this multilabel approach was unsucessful, and is simply was fitting noise, with no actual underlaying patterns getting identified. I didn't mention it, but when we looked at the correlation plots and PCA there was another hint this might be the case, but I'll get to that. There is evedently not enough information in my dataset to differentiate this many labels across these 2 dimensions. So..I wanted to have a better model (5:20)
-
I figured I could simplify my problem. Instead of predicting the tempering conditions directly using the alloy properties and the final hardness, I could predict the continuous final hardness measure from the tempering conditions and alloy properties. A lot of my code was simply able to be reused by swapping the target dimensions. I chose a Gradient Boosting Regression model, and again a Neural Network model to compare. As seen in the R-squared values, the gradient boosting regression model performed very comparibly with the neural network regresssion model. The plot on the right clearly shows that the gradient boosting regression model fits the data quite well, and there are not underlaying patterns it is missing. Therefore, I would not expect much improvement in R-squared to be possible without overfitting due to the scatter of the actual data. This particular plot is done using the inverse transform of the target-scaled data, so the predicted an actual hardnesses shown are the same Rockwell hardness measure (HRC diamond sphere) from the raw dataset. (6:30)
-
Now that I have a satisfactory model I wanted to revist what may have been the cause of the failure of the first approach. On the left I have the loss of the Classification Neural Network model and on the right I have the loss of the regression neural network model. Originally, when looking at the classifcation neural network results it was clear it struggled to predict tempering time, but looking at the loss history it is evident it failed to improve over generations for time dimension at all. If we looked back at the correlation plot, I left both targets in the plot, but there is no essentially correlation between tempering time and any other feature. This supports the idea i mentioned earlier that the data is insufficent for the mutli-output classification problem, and that these models are just fitting noise, especially in the tempering time case. I had the thought that I could predict them as paired units, 55 classes, as opposed to 5 and 11 independant classes... however, my dataset is small enough I would only have only 20-25 rows of support per class in that case, which is insufficent. (7:35)
-
Revisiting the goal of the problem. I aimed to make an engineering tool that would predict the tempering conditions needed to reach a desired final hardness. Having failed to predict the tempering conditions directly, future work would either need to increase the size of the dataset to prevent fitting only to noise, or implement a search algorythem around a simpler regression model to suggest the tempering conditions through modelling the hardness. The application would look much the same as originally envisioned: input a steel and desired final hardness, then output the tempering conditions. Under the hood however it would generate batches of tempering conditions, predict the batch of hardness outputs from the model, then itterate with a search algorythem to close in on the desired hardness, then output the set of tempering conditions that correspond. (8:00)
-
In terms of next steps to be taken, I would like to develop an explainable model. Using PCA as I did confounds the ability to pull explainations from the regression model. I do not know what dataset features correspons to the 7 dominant PCA features in this plot of feature importance. It could be that PCA is cluing into the atomic size of the alloying elements and that is a dominant feature in this behavior, but I can not learn that from this model. Figuring out how to implement some inverse_transformations, or skipping the PCA altogether and handling the mutlicollinearity another way would be important in gaining insights from this model. I know certain alloying elements have a much larger impact on hardness and tempering behaviors, so perhaps using using external domain knowledge and validation testing, someone more knowledgable than I may be able to assign signficance to the PCA model features. I think this could be an interesting line of future inquery, but is outside the scope of this project.(9:00)
-
Thank you for your time, I hope this was interesting! Elias, do we have time for questions? (9:10)
- Goal-Oriented: Start with a clear understanding of the purpose of your presentation. What are you trying to convey? Is it to inform, persuade, or explore data? Define your key message or insight.
- Target Audience: Tailor your visualizations and explanations to the knowledge level and interests of your audience. Consider what they need to know and how best to communicate that information to them.
- Relevant Data: for example, if your story is about hourly changes in rainfall, your visualization data shouldn’t be in months.
- Contextualization: if warranted, provide context for the data. Explain where it comes from, the time period it covers, and any assumptions or limitations.
- Choosing the Right Chart Type: Use appropriate visualizations (bar charts, line graphs, scatter plots, etc.) that best represent the data and the insights you want to convey.
- Simplicity: Avoid clutter and unnecessary details. Strive for simplicity in design while ensuring all necessary information is included.
- Consistency: Maintain consistent use of colors, fonts, and design elements throughout the presentation to avoid confusion and enhance readability.
- Accessibility [OPTIONAL]: Ensure that the design is accessible to all viewers, including those with color blindness or other visual impairments. Use color palettes that are colorblind-friendly and provide sufficient contrast.
| Slide | Story Beat | Content |
|---|---|---|
| 1 | introduce the subject | Hook, we've all bent metal til it breaks. manufacturing |
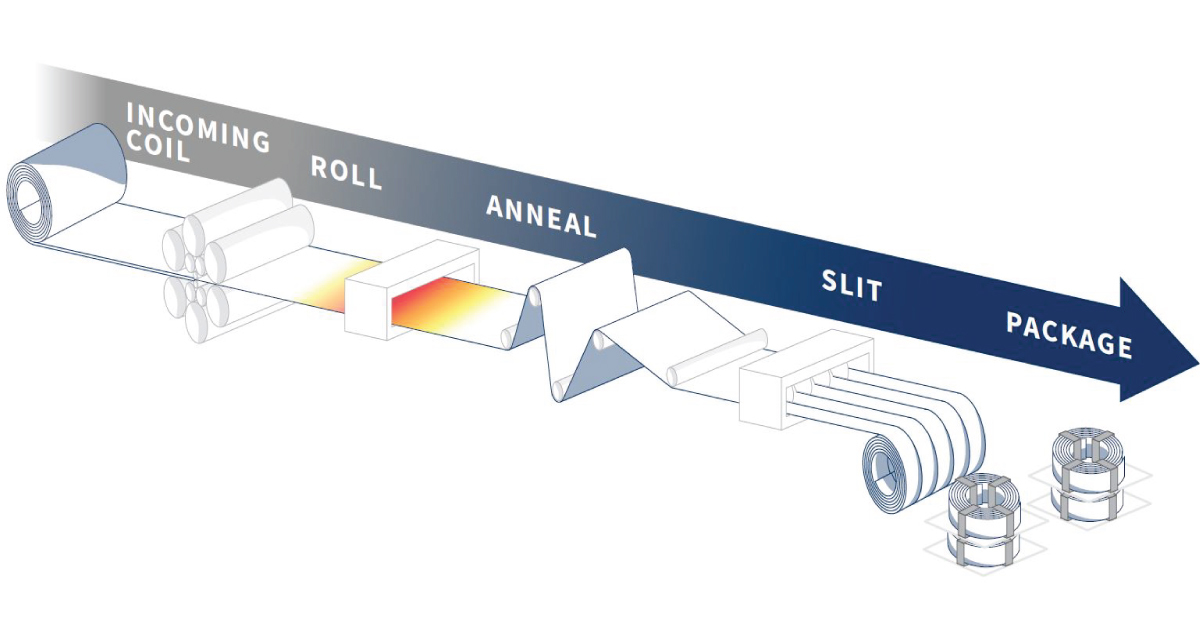
| 2 | describe the base problem and solution (work and temper) | https://d2ykdomew87jzd.cloudfront.net/Blog/Ulbrich-Manufacturing-Process-Illustration-1200x628.jpg |
| 3 | introduce the data and modelling goal | data summary table. ref Raiipa, AZoM, MIF |
| 4 | data processing, PCA | obviously there were a few fields like source that were unnecessary for my consideration. correlation plots |
| 5 | structure of multioutput problem | label balancing, pre/post. accuracy... didn't work. two headed model diagram. |
| 6 | return to a simpler regression problem | introduce the regression problem, and the prediction. scatter/ling plot. table of R2 for NN and GBR |
| 7 | compare NN model results across the two problems | plot 2 headed loss on left, single regression on right. |
| 8 | Downsides of the data processing | talk about GBR explainability and PCA. Feature importance plot. inability to correlate with features irl.know from domain knowlegde alloy elements significantly change steel microstructure behavior at temperature. show Mo plot from paper. https://www.semanticscholar.org/paper/Christian-Doppler-Laboratory-for-Early-Stages-of-of-Maalekian/8b2503ef6e92e0452156547acb3f59e6c53e266c |
| 9 | Thank you! |
{kind=link}