[TOC]
Java字节码是Java虚拟机执行的一种指令格式.class文件是编译器编译之后供虚拟机解释执行的二进制字节码文件.Java虚拟机只认字节码,而不会在意这字节码是通过哪个语言(比如Groovy,JRuby,Jython等)编译出来的。形成了Java虚拟机与语言之间的解耦。
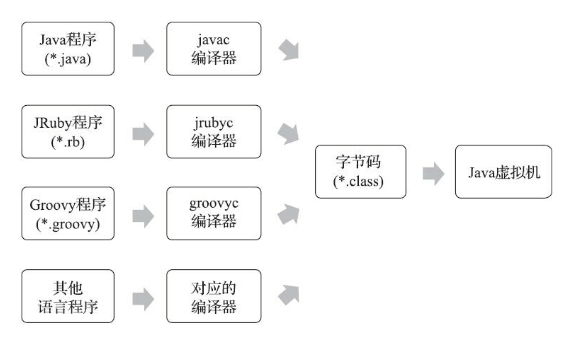
下面举个例子,写一段Java打码,并编译.
package com.xfhy.test;
public class Hello {
private int num = 1;
public int add() {
num = num + 2;
return num;
}
}编译得到class文件之后,用Hex Fiend软件打开该class文件.
CAFEBABE 00000034 00130A00 04000F09 00030010 07001107 00120100 036E756D
01000149 0100063C 696E6974 3E010003 28295601 0004436F 64650100 0F4C696E
654E756D 62657254 61626C65 01000361 64640100 03282949 01000A53 6F757263
6546696C 6501000A 48656C6C 6F2E6A61 76610C00 0700080C 00050006 01001363
6F6D2F78 6668792F 74657374 2F48656C 6C6F0100 106A6176 612F6C61 6E672F4F
626A6563 74002100 03000400 00000100 02000500 06000000 02000100 07000800
01000900 00002600 02000100 00000A2A B700012A 04B50002 B1000000 01000A00
00000A00 02000000 03000400 04000100 0B000C00 01000900 00002B00 03000100
00000F2A 2AB40002 0560B500 022AB400 02AC0000 0001000A 0000000A 00020000
0007000A 00080001 000D0000 0002000E
class文件内部就是长这个样子. 里面是一堆16进制字节,完全看不懂.JVM是如何解读的?
class文件格式采用一种类似于C语言结构体的伪结构来存储数据,这种伪结构只有两种数据类型: 无符号数和表.
- 无符号数: 无符号数可以用来描述数字、索引引用、数量值或按照utf-8编码构成的字符串值.其中无符号数属于基本的数据类型。 以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节和8个字节.
- 表: 表是由多个无符号数或其他表构成的复合数据结构.所有的表都以“_info”结尾,由于表没有固定长度,所以通常会在其前面加上个数说明.
class文件结构,JVM加载某个class文件时,就是根据下面的结构顺序去解析class文件,加载class文件到内存中,并在内存中分配相应的空间:
- 魔数:表示这是class字节码文件
- 版本号:jdk 版本号
- 常量池:类的各种相关信息,如类的名称、父类的名称、类中的方法名、参数名称、参数类型等,这些信息都是以各种表的形式保存咋子常量池中
- 访问标志:public、volatile之类的
- 类/父类/接口:当前类是谁、父类是哪个、实现接口是哪些
- 字段描述集合:各字段的描述
- 方法描述集合:各方法的描述
- 属性描述集合:Class文件、字段表、方法表都可以携带自己的属性表集合,以描述某些场景专有的信息
相邻项之间没有任何空隙,只需要按照这个顺序逐一进行解读就可以了,下表中还规定了某一种数据结构需要占用多大的空间:
| 类型 | 名称 | 说明 | 长度 |
|---|---|---|---|
| u4 | magic | 魔数,识别 Class 文件格式 | 4 个字节 |
| u2 | minor_version | 副版本号 | 2 个字节 |
| u2 | major_version | 主版本号 | 2 个字节 |
| u2 | constant_pool_count | 常量池计算器 | 2 个字节 |
| cp_info | constant_pool | 常量池 | n 个字节 |
| u2 | access_flags | 访问标志 | 2 个字节 |
| u2 | this_class | 类索引 | 2 个字节 |
| u2 | super_class | 父类索引 | 2 个字节 |
| u2 | interfaces_count | 接口计数器 | 2 个字节 |
| u2 | interfaces | 接口索引集合 | 2 个字节 |
| u2 | fields_count | 字段个数 | 2 个字节 |
| field_info | fields | 字段集合 | n 个字节 |
| u2 | methods_count | 方法计数器 | 2 个字节 |
| method_info | methods | 方法集合 | n 个字节 |
| u2 | attributes_count | 附加属性计数器 | 2 个字节 |
| attribute_info | attributes | 附加属性集合 | n 个字节 |
用于标记当前文件是class(为啥不是用后缀来标记该文件为class文件,因为防止后缀被修改,为了安全),固定值为0XCAFEBABE.文件一开始就是这个.
魔数后面的00000034是版本号,也是4个字节,其中前2个字节表示副版本号,后2个字节表示主版本号.这里0034对应的值是52,也就是jdk 1.8.0
接着是常量池相关的东西了,常量池的数量不固定,需要2个字节来表示常量池容量计数值.demo里面是0013,也就是19.
咱通过javap -verbose Hello命令查看该class的字节码如下(只截取了常量池部分数据):
Constant pool:
#1 = Methodref #4.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #3.#16 // com/xfhy/test/Hello.num:I
#3 = Class #17 // com/xfhy/test/Hello
#4 = Class #18 // java/lang/Object
#5 = Utf8 num
#6 = Utf8 I
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 add
#12 = Utf8 ()I
#13 = Utf8 SourceFile
#14 = Utf8 Hello.java
#15 = NameAndType #7:#8 // "<init>":()V
#16 = NameAndType #5:#6 // num:I
#17 = Utf8 com/xfhy/test/Hello
#18 = Utf8 java/lang/Object
可以看到这里其实序号是从1开始的,而且总共是18个??? 那为啥class文件里面的数值是19?因为它把第0项常量空出来了:这是为了在于满足后面某些指向常量池的索引值的数据在特定情况下需要表达"不引用任何一个常量池项目"的含义,这种情况可用索引值0来表示.
首先是第一个常量0x0a,即10.这里的10代表的是CONSTANT_Methodref_info,即类中方法的符号引用. 常量池中的每一项都是一个表,常量标志数值的含义表:
| 类型 | 标志 | 描述 |
|---|---|---|
| CONSTANT_utf8_info | 1 | UTF-8 编码的字符串 |
| CONSTANT_Integer_info | 3 | 整形字面量 |
| CONSTANT_Float_info | 4 | 浮点型字面量 |
| CONSTANT_Long_info | 5 | 长整型字面量 |
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
| CONSTANT_String_info | 8 | 字符串类型字面量 |
| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
| CONSTANT_NameAndType_info | 12 | 字段或方法的符号引用 |
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
| CONSTANT_MothodType_info | 16 | 标志方法类型 |
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
什么是符号引用? 常量池主要存放两大常量,字面量和符号引用.
- 字面量: 文本字符串,声明为final的常量值
- 符号引用: 类和接口的全限定名,字段的名称和描述符,方法的名称和描述符
常量池中的每一个都会有一个u1大小的tag值。tag值是表的标识,JVM解析class文件时,通过这个值来判断当前数据结构是哪一种表。以上14种表都有自己的结果。这里简单介绍一下CONSTANT_Class_info 和 CONSTANT_Utf8_info 这两张表用以举例说明,其他表是类似的。
CONSTANT_Class_info表具体结构如下:
table CONSTANT_Class_info {
u1 tag = 7;
u2 name_index;
}
- tag:占用一个字节大小。比如值是7,说明是
CONSTANT_Class_info类型表 name_index:是一个索引值,可以将它理解为一个指针,指向常量池中索引为name_index的常量表。比如name_index=2,则它指向常量池中第2个常量。
接下来再看一下CONSTANT_Utf8_info表具体结构:
table CONSTANT_utf8_info {
u1 tag;
u2 length;
u1[] bytes;
}
- tag:值为1,表示
CONSTANT_Utf8_info类型的表 - length:表示u1[]的长度,比如length=5,则表示接下来的数据是5个连续的u1类型数据
- bytes:u1类型数组,长度为上面第2个参数length的值
知道了该标志的含义,说明接下来的数据就是类中方法的符号引用的数据.但是我们不知道这个数据到底有多长.得看下面这个表格,常量池中的17种数据类型的结构总表,才知道它的结构到底如何:
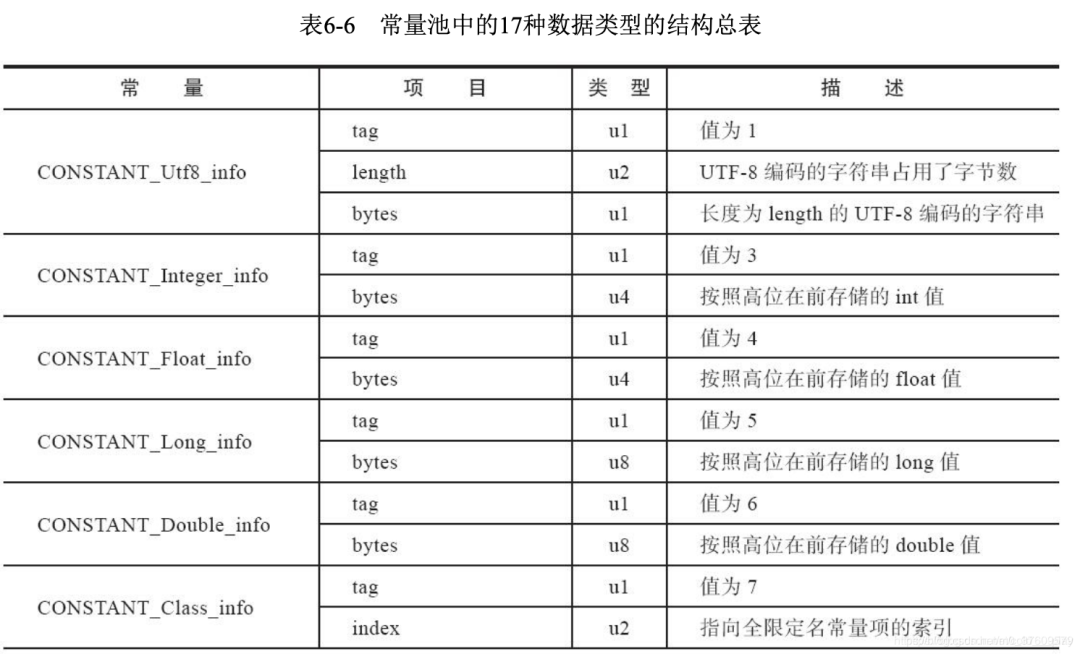
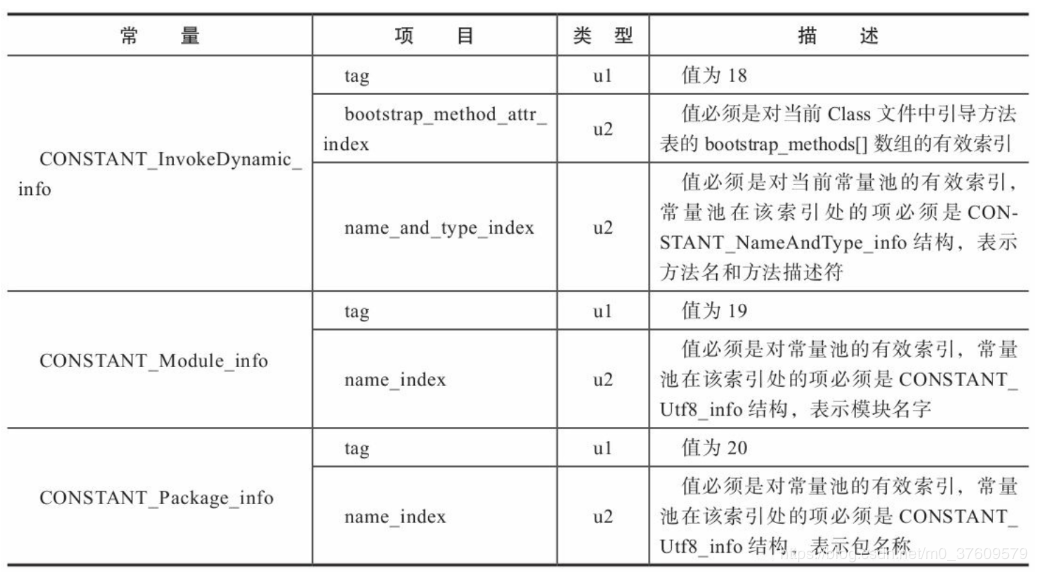
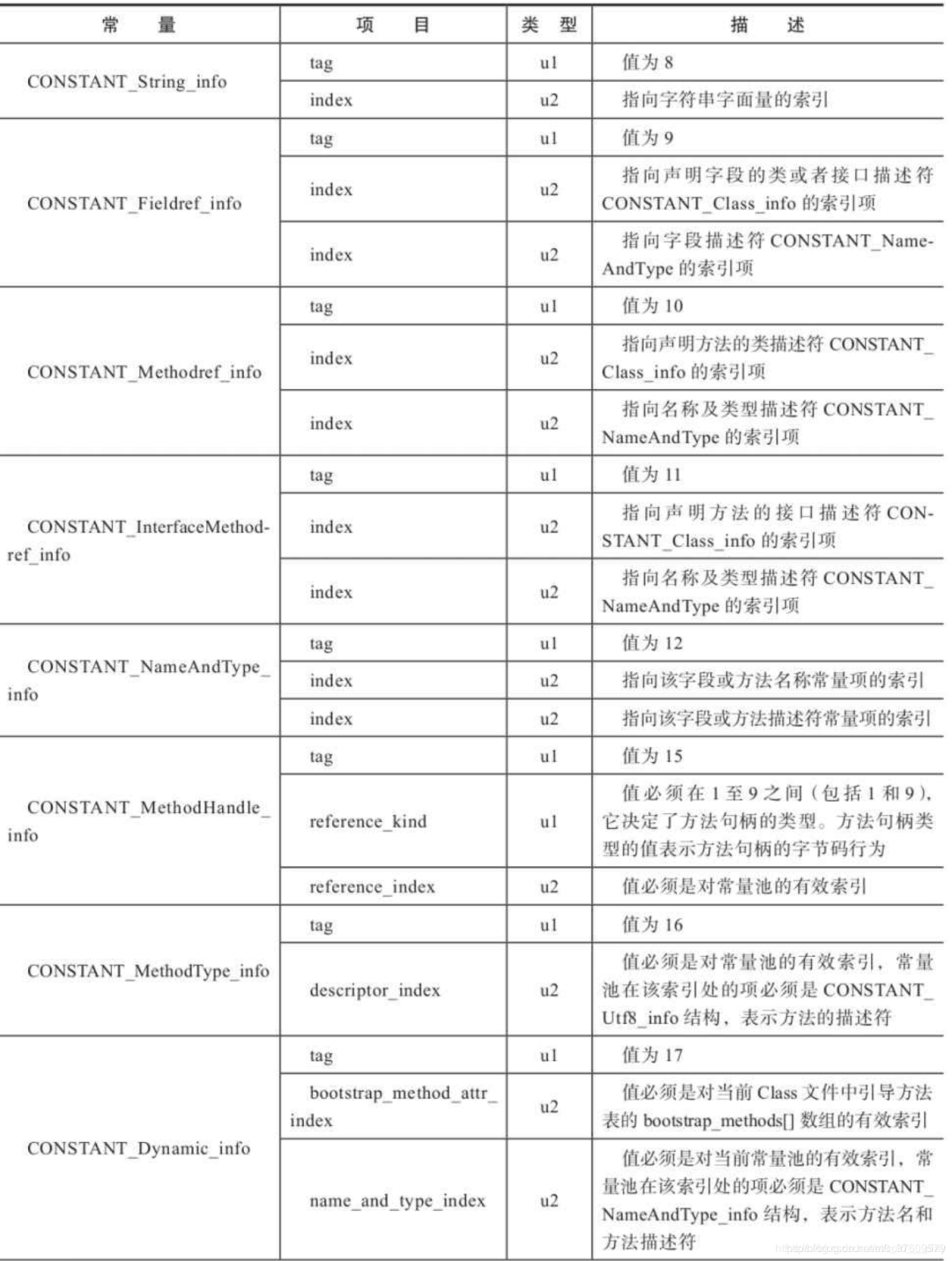
从表中查出CONSTANT_Methodref_info的tag是10,上面已经拿到了.然后接下来的2个u2表示它的数据,在demo中的值为: 0004 000F
- 前两位的值为
0x0004,即 4,指向常量池第 4 项的索引 - 后两位的值为
0x000f,即 15,指向常量池第 15 项的索引
至此,第一个常量就解读完毕了.后面还有17个常量,就不一一解读了,就是查字典.所有的常量都在这里了,它们最后的解读出来是和javap -verbose Hello解读出来的Constant pool是一致的.
0A00 04000F09 00030010 07001107 00120100 036E756D
01000149 0100063C 696E6974 3E010003 28295601 0004436F 64650100 0F4C696E
654E756D 62657254 61626C65 01000361 64640100 03282949 01000A53 6F757263
6546696C 6501000A 48656C6C 6F2E6A61 76610C00 0700080C 00050006 01001363
6F6D2F78 6668792F 74657374 2F48656C 6C6F0100 106A6176 612F6C61 6E672F4F
626A6563 74
常量池过了就是访问标志了,用两个字节来表示,其标识了类或者接口的访问信息,比如:该 Class 文件是类还是接口,是否被定义成public,是否是abstract,如果是类,是否被声明成final等等。各种访问标志如下所示:
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 是否为 Public 类型 |
| ACC_FINAL | 0x0010 | 是否被声明为 final,只有类可以设置 |
| ACC_SUPER | 0x0020 | 是否允许使用 invokespecial 字节码指令的新语义,JDK1.0.2 之后编译出来的类的这个标志默认为真 |
| ACC_INTERFACE | 0x0200 | 标志这是一个接口 |
| ACC_ABSTRACT | 0x0400 | 是否为 abstract 类型,对于接口或者抽象类来说,次标志值为真,其他类型为假 |
| ACC_SYNTHETIC | 0x1000 | 标志这个类并非由用户代码产生 |
| ACC_ANNOTATION | 0x2000 | 标志这是一个注解 |
| ACC_ENUM | x4000 | 标志这是一个枚举 |
在本demo中是0021,为了方便寻找,我加了~~将该位置数据间隔开.
CAFEBABE 00000034 00130A00 04000F09 00030010 07001107 00120100 036E756D
01000149 0100063C 696E6974 3E010003 28295601 0004436F 64650100 0F4C696E
654E756D 62657254 61626C65 01000361 64640100 03282949 01000A53 6F757263
6546696C 6501000A 48656C6C 6F2E6A61 76610C00 0700080C 00050006 01001363
6F6D2F78 6668792F 74657374 2F48656C 6C6F0100 106A6176 612F6C61 6E672F4F
626A6563 74~~0021~~00 03000400 00000100 02000500 06000000 02000100 07000800
01000900 00002600 02000100 00000A2A B700012A 04B50002 B1000000 01000A00
00000A00 02000000 03000400 04000100 0B000C00 01000900 00002B00 03000100
00000F2A 2AB40002 0560B500 022AB400 02AC0000 0001000A 0000000A 00020000
0007000A 00080001 000D0000 0002000E
0x0021就是0x0001和0x0020的并集,即就是public.
- 访问标志后的两个字节就是类索引
- 类索引后的两个字节就是父类索引
- 父类索引后的两个字节则是接口索引计数器
我将数据标记了一下:
CAFEBABE 00000034 00130A00 04000F09 00030010 07001107 00120100 036E756D
01000149 0100063C 696E6974 3E010003 28295601 0004436F 64650100 0F4C696E
654E756D 62657254 61626C65 01000361 64640100 03282949 01000A53 6F757263
6546696C 6501000A 48656C6C 6F2E6A61 76610C00 0700080C 00050006 01001363
6F6D2F78 6668792F 74657374 2F48656C 6C6F0100 106A6176 612F6C61 6E672F4F
626A6563 740021~~00 03000400 00~~000100 02000500 06000000 02000100 07000800
01000900 00002600 02000100 00000A2A B700012A 04B50002 B1000000 01000A00
00000A00 02000000 03000400 04000100 0B000C00 01000900 00002B00 03000100
00000F2A 2AB40002 0560B500 022AB400 02AC0000 0001000A 0000000A 00020000
0007000A 00080001 000D0000 0002000E
类索引的值为0x0003, 即为指向常量池中第三项的索引com/xfhy/test/Hello,这里用到了常量池,通过类索引可以确定类的全限定名.
父类索引的值为0x0004,即为指向常量池中第4项的索引java/lang/Object,类都是继承自Object的.
然后是接口计数器0x0000,这里没有接口,所以是0.
这里本来接下来是接口索引集合的,但是这里没有用,所以不占数据空间.
字段表用来描述类或者接口中声明的变量.这里的字段包含了类级别变量以及实例变量,但是不包括方法内部声明的局部变量.
字段表里面包含了以下几个数据:
| 类型 | 名称 | 含义 | 数量 |
|---|---|---|---|
| u2 | access_flags | 访问标志 | 1 |
| u2 | name_index | 字段名索引 | 1 |
| u2 | descriptor_index | 描述符索引 | 1 |
| u2 | attributes_count | 属性计数器 | 1 |
| attribute_info | attributes | 属性集合 | attributes_count |
我将数据标记了一下:
CAFEBABE 00000034 00130A00 04000F09 00030010 07001107 00120100 036E756D
01000149 0100063C 696E6974 3E010003 28295601 0004436F 64650100 0F4C696E
654E756D 62657254 61626C65 01000361 64640100 03282949 01000A53 6F757263
6546696C 6501000A 48656C6C 6F2E6A61 76610C00 0700080C 00050006 01001363
6F6D2F78 6668792F 74657374 2F48656C 6C6F0100 106A6176 612F6C61 6E672F4F
626A6563 74002100 03000400 00~~000100 02000500 060000~~00 02000100 07000800
01000900 00002600 02000100 00000A2A B700012A 04B50002 B1000000 01000A00
00000A00 02000000 03000400 04000100 0B000C00 01000900 00002B00 03000100
00000F2A 2AB40002 0560B500 022AB400 02AC0000 0001000A 0000000A 00020000
0007000A 00080001 000D0000 0002000E
值为0x0001,因为只有一个字段.
接下来将demo中的这个字段进行分析一下,首先是字段表访问标志,这里的值是0x0002,是什么含义呢?得看下面这张表
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 字段是否为 public |
| ACC_PRIVATE | 0x0002 | 字段是否为 private |
| ACC_PROTECTED | 0x0004 | 字段是否为 protected |
| ACC_STATIC | 0x0008 | 字段是否为 static |
| ACC_FINAL | 0x0010 | 字段是否为 final |
| ACC_VOLATILE | 0x0040 | 字段是否为 volatile |
| ACC_TRANSTENT | 0x0080 | 字段是否为 transient |
| ACC_SYNCHETIC | 0x1000 | 字段是否为由编译器自动产生 |
| ACC_ENUM | 0x4000 | 字段是否为 enum |
值是0x0002代表着private修饰符.
- 访问标志的值为
0x0002,查询上面字段访问标志的表格,可得字段为private; - 字段名索引的值为
0x0005, 查询常量池中的第 5 项, 可得:num - 描述符索引的值为
0x0006, 查询常量池中的第 6 项, 可得:I - 属性计数器的值为
0x0000, 即没有任何的属性.
注意:
- 字段表集合中不会列出从父类或者父接口中继承而来的字段
- 内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段
接下来是方法表,前面两个字节依然用来表示方法表的容量,我将数据标记了一下:
CAFEBABE 00000034 00130A00 04000F09 00030010 07001107 00120100 036E756D
01000149 0100063C 696E6974 3E010003 28295601 0004436F 64650100 0F4C696E
654E756D 62657254 61626C65 01000361 64640100 03282949 01000A53 6F757263
6546696C 6501000A 48656C6C 6F2E6A61 76610C00 0700080C 00050006 01001363
6F6D2F78 6668792F 74657374 2F48656C 6C6F0100 106A6176 612F6C61 6E672F4F
626A6563 74002100 03000400 00000100 02000500 060000~~00 02000100 07000800
010009~~00 00002600 02000100 00000A2A B700012A 04B50002 B1000000 01000A00
00000A00 02000000 03000400 04000100 0B000C00 01000900 00002B00 03000100
00000F2A 2AB40002 0560B500 022AB400 02AC0000 0001000A 0000000A 00020000
0007000A 00080001 000D0000 0002000E
方法表的容量为0x0002,即demo中有2个方法(还有1个默认的构造方法,别忘了..).
既然是表,那肯定有结构,还有严格的顺序规定.
| 类型 | 名称 | 含义 | 数量 |
|---|---|---|---|
| u2 | access_flags | 访问标志 | 1 |
| u2 | name_index | 方法名索引 | 1 |
| u2 | descriptor_index | 描述符索引 | 1 |
| u2 | attributes_count | 属性计数器 | 1 |
| attribute_info | attributes | 属性集合 | attributes_count |
方法也是有访问标志的
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 方法是否为 public |
| ACC_PRIVATE | 0x0002 | 方法是否为 private |
| ACC_PROTECTED | 0x0004 | 方法是否为 protected |
| ACC_STATIC | 0x0008 | 方法是否为 static |
| ACC_FINAL | 0x0010 | 方法是否为 final |
| ACC_SYHCHRONRIZED | 0x0020 | 方法是否为 synchronized |
| ACC_BRIDGE | 0x0040 | 方法是否是有编译器产生的方法 |
| ACC_VARARGS | 0x0080 | 方法是否接受参数 |
| ACC_NATIVE | 0x0100 | 方法是否为 native |
| ACC_ABSTRACT | 0x0400 | 方法是否为 abstract |
| ACC_STRICTFP | 0x0800 | 方法是否为 strictfp |
| ACC_SYNTHETIC | 0x1000 | 方法是否是有编译器自动产生的 |
第一个方法是:
000100 07000800 010009
- 访问标志的值为
0x0001,查询上面字段访问标志的表格,可得字段为 public; - 方法名索引的值为
0x0007,查询常量池中的第 7 项,可得:<init> - 这个名为
<init>的方法实际上就是默认的构造方法了。 - 描述符索引的值为
0x0008,查询常量池中的第 8 项,可得:()V - 属性计数器的值为
0x0001,即这个方法表有一个属性。 - 属性计数器后面就是属性表了,由于只有一个属性,所以这里也只有一个属性表。
由于涉及到属性表,这里简单说下,下一节会详细介绍。
属性表的前两个字节是属性名称索引,这里的值为0x0009, 查下常量池中的第 9 项:Code.即这是一个Code属性,我们方法里面的代码就是存放在这个 Code 属性里面。相关细节暂且不表。下一节会详细介绍 Code 属性。
先跳过属性表,我们再来看下第二个方法: 000100 0B000C00 010009
- 访问标志的值为
0x0001,查询上面字段访问标志的表格,可得字段为 public; - 方法名索引的值为
0x000b,查询常量池中的第 11 项,可得:add - 描述符索引的值为
0x000c,查询常量池中的第 12 项,可得:()I - 属性计数器的值为
0x0001,即这个方法表有一个属性。 - 属性名称索引的值同样也是
0x0009,即这是一个 Code 属性。 可以看到,第二个方法表就是我们自定义的add()方法了。
上面提到了属性表,现在我们来看一下属性表是什么.
Class文件、字段表、方法表都可以携带自己的属性表集合,以描述某些场景专有的信息。不再要求各个属性表具有严格顺序,并且允许只要不与已有属性名重复,任何人实现的编译器都可以向属性表中写入自定义的属性信息,Java虚拟机运行时会忽略掉它不认识的属性。
属性表实际上有很多类型,上面看到的Code属性只是其中一个.
| 属性名称 | 使用位置 | 含义 |
|---|---|---|
| Code | 方法表 | Java 代码编译成的字节码指令 |
| ConstantValue | 字段表 | final 关键字定义的常量池 |
| Deprecated | 类,方法,字段表 | 被声明为 deprecated 的方法和字段 |
| Exceptions | 方法表 | 方法抛出的异常 |
| EnclosingMethod | 类文件 | 仅当一个类为局部类或者匿名类是才能拥有这个属性,这个属性用于标识这个类所在的外围方法 |
| InnerClass | 类文件 | 内部类列表 |
| LineNumberTable | Code 属性 | Java 源码的行号与字节码指令的对应关系 |
| LocalVariableTable | Code 属性 | 方法的局部便狼描述 |
| StackMapTable | Code 属性 | JDK1.6 中新增的属性,供新的类型检查检验器检查和处理目标方法的局部变量和操作数有所需要的类是否匹配 |
| Signature | 类,方法表,字段表 | 用于支持泛型情况下的方法签名 |
| SourceFile | 类文件 | 记录源文件名称 |
| SourceDebugExtension | 类文件 | 用于存储额外的调试信息 |
| Synthetic | 类,方法表,字段表 | 标志方法或字段为编译器自动生成的 |
| LocalVariableTypeTable | 类 | 使用特征签名代替描述符,是为了引入泛型语法之后能描述泛型参数化类型而添加 |
| RuntimeVisibleAnnotations | 类,方法表,字段表 | 为动态注解提供支持 |
| RuntimeInvisibleAnnotations | 表,方法表,字段表 | 用于指明哪些注解是运行时不可见的 |
| RuntimeVisibleParameterAnnotation | 方法表 | 作用与 RuntimeVisibleAnnotations 属性类似,只不过作用对象为方法 |
| RuntimeInvisibleParameterAnnotation | 方法表 | 作用与 RuntimeInvisibleAnnotations 属性类似,作用对象哪个为方法参数 |
| AnnotationDefault | 方法表 | 用于记录注解类元素的默认值 |
| BootstrapMethods | 类文件 | 用于保存 invokeddynamic 指令引用的引导方式限定符 |
对于每一个属性,它的名称都要从常量池中引用一个CONSTANT_Utf8_info类型的常量来表示,而属性值的结构则是完全自定义的,只需要用过一个u4的长度属性去说明属性值所占用的位数即可。
知道了属性之后,还得知道该属性对应的结构,然后才能解析出来:
| 类型 | 名称 | 数量 | 含义 |
|---|---|---|---|
| u2 | attribute_name_index | 1 | 属性名索引 |
| u4 | attribute_length | 1 | 属性长度 |
| u1 | info | attribute_length | 属性表 |
可以看到这里的属性表其实只是定义了属性的长度,里面还有一个表用来自定义的,是不定长的,具体的结构是自己去定义的.
这里只单独介绍一下Code属性。Java程序方法体里面的代码经过javac编译器处理之后,最终变为字节码指令存储在Code属性内。Code属性出现在方法表的属性集合之中,但并非所有的方法表都必须存在这个属性,比如接口或者抽象方法就不存在Code属性。
Code属性表结构:
| 类型 | 名称 | 数量 | 含义 |
|---|---|---|---|
| u2 | attribute_name_index | 1 | 属性名索引 |
| u4 | attribute_length | 1 | 属性长度 |
| u2 | max_stack | 1 | 操作数栈深度的最大值 |
| u2 | max_locals | 1 | 局部变量表所需的存续空间 |
| u4 | code_length | 1 | 字节码指令的长度 |
| u1 | code | code_length | 存储字节码指令 |
| u2 | exception_table_length | 1 | 异常表长度 |
| exception_info | exception_table | exception_length | 异常表 |
| u2 | attributes_count | 1 | 属性集合计数器 |
| attribute_info | attributes | attributes_count | 属性集合 |
attribute_name_index是一项指向CONSTANT_Utf8_info型常量的索引,此常量值固定为“Code”。
max_stack代表了操作数栈深度的最大值。在方法执行的任意时刻,操作数栈都不会超过这个深度。虚拟机运行的时候需要根据这个值来分配栈帧中的操作栈深度。
max_locals代表了局部变量表所需的存储空间。在这里,max_locals的单位是变量槽(Slot),变量槽是虚拟机为局部变量分配内存所使用的最小单位。对于byte、char、float、int、short、boolean和returnAddress等长度不超过32位的数据类型,每个局部变量占用一个变量槽,而double和long这两种64位的数据类型则需要两个变量槽来存放。方法参数(包括实例方法中的隐藏参数“this”)、显式异常处理程序中的参数(即try-catch语句中catch块中所定义的异常)、方法体中定义的局部变量都需要依赖局部变量表来存放。注意,并不是在方法中用了多少个局部变量,就把这些局部变量所占变量槽数量之和作为max_locals的值,操作数栈和局部变量表直接决定一个该方法的栈帧所耗费的内存,不必要的操作数栈深度和变量槽数量会造成内存的浪费。Java虚拟机的做法是将局部变量表中的变量表进行重用,当代码执行超出一个局部变量的作用域时,这个局部变量所占的变量槽可以被其他局部变量所使用,javac编译器会根据变量的作用域来分配变量槽给各个变量使用,根据同时生存的最大局部变量数量和类型计算出max_locals的大小。
code_length和code用来存储Java源程序编译后生成的字节码指令。code_length代表字节码长度,code是用于存储字节码指令的一系列字节流。
Code属性表的前两项是和属性表是一致的,Code属性是遵循属性表的结构,后面那些是它自定义的结构.
这里我就不再一一去解读Code属性了,就是查字典.
我们可以一步到位,使用javap -verbose Hello可以得到得到字节码指令
public com.xfhy.test.Hello();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: iconst_1
6: putfield #2 // Field num:I
9: return
LineNumberTable:
line 3: 0
line 4: 4
public int add();
descriptor: ()I
flags: ACC_PUBLIC
Code:
stack=3, locals=1, args_size=1
0: aload_0
1: aload_0
2: getfield #2 // Field num:I
5: iconst_2
6: iadd
7: putfield #2 // Field num:I
10: aload_0
11: getfield #2 // Field num:I
14: ireturn
LineNumberTable:
line 7: 0
line 8: 10
这里涉及到一些字节码指令,这些指令含义如下表:
| 字节码 | 助记符 | 指令含义 |
|---|---|---|
| 0x00 | nop | 什么都不做 |
| 0x01 | aconst_null | 将 null 推送至栈顶 |
| 0x02 | iconst_m1 | 将 int 型 - 1 推送至栈顶 |
| 0x03 | iconst_0 | 将 int 型 0 推送至栈顶 |
| 0x04 | iconst_1 | 将 int 型 1 推送至栈顶 |
| 0x05 | iconst_2 | 将 int 型 2 推送至栈顶 |
| 0x06 | iconst_3 | 将 int 型 3 推送至栈顶 |
| 0x07 | iconst_4 | 将 int 型 4 推送至栈顶 |
| 0x08 | iconst_5 | 将 int 型 5 推送至栈顶 |
| 0x09 | lconst_0 | 将 long 型 0 推送至栈顶 |
| 0x0a | lconst_1 | 将 long 型 1 推送至栈顶 |
| 0x0b | fconst_0 | 将 float 型 0 推送至栈顶 |
| 0x0c | fconst_1 | 将 float 型 1 推送至栈顶 |
| 0x0d | fconst_2 | 将 float 型 2 推送至栈顶 |
| 0x0e | dconst_0 | 将 do le 型 0 推送至栈顶 |
| 0x0f | dconst_1 | 将 do le 型 1 推送至栈顶 |
| 0x10 | bipush | 将单字节的常量值 (-128~127) 推送至栈顶 |
| 0x11 | sipush | 将一个短整型常量值 (-32768~32767) 推送至栈顶 |
| 0x12 | ldc | 将 int, float 或 String 型常量值从常量池中推送至栈顶 |
| 0x13 | ldc_w | 将 int, float 或 String 型常量值从常量池中推送至栈顶(宽索引) |
| 0x14 | ldc2_w | 将 long 或 do le 型常量值从常量池中推送至栈顶(宽索引) |
| 0x15 | iload | 将指定的 int 型本地变量 |
| 0x16 | lload | 将指定的 long 型本地变量 |
| 0x17 | fload | 将指定的 float 型本地变量 |
| 0x18 | dload | 将指定的 do le 型本地变量 |
| 0x19 | aload | 将指定的引用类型本地变量 |
| 0x1a | iload_0 | 将第一个 int 型本地变量 |
| 0x1b | iload_1 | 将第二个 int 型本地变量 |
| 0x1c | iload_2 | 将第三个 int 型本地变量 |
| 0x1d | iload_3 | 将第四个 int 型本地变量 |
| 0x1e | lload_0 | 将第一个 long 型本地变量 |
| 0x1f | lload_1 | 将第二个 long 型本地变量 |
| 0x20 | lload_2 | 将第三个 long 型本地变量 |
| 0x21 | lload_3 | 将第四个 long 型本地变量 |
| 0x22 | fload_0 | 将第一个 float 型本地变量 |
| 0x23 | fload_1 | 将第二个 float 型本地变量 |
| 0x24 | fload_2 | 将第三个 float 型本地变量 |
| 0x25 | fload_3 | 将第四个 float 型本地变量 |
| 0x26 | dload_0 | 将第一个 do le 型本地变量 |
| 0x27 | dload_1 | 将第二个 do le 型本地变量 |
| 0x28 | dload_2 | 将第三个 do le 型本地变量 |
| 0x29 | dload_3 | 将第四个 do le 型本地变量 |
| 0x2a | aload_0 | 将第一个引用类型本地变量 |
| 0x2b | aload_1 | 将第二个引用类型本地变量 |
| 0x2c | aload_2 | 将第三个引用类型本地变量 |
| 0x2d | aload_3 | 将第四个引用类型本地变量 |
| 0x2e | iaload | 将 int 型数组指定索引的值推送至栈顶 |
| 0x2f | laload | 将 long 型数组指定索引的值推送至栈顶 |
| 0x30 | faload | 将 float 型数组指定索引的值推送至栈顶 |
| 0x31 | daload | 将 do le 型数组指定索引的值推送至栈顶 |
| 0x32 | aaload | 将引用型数组指定索引的值推送至栈顶 |
| 0x33 | baload | 将 boolean 或 byte 型数组指定索引的值推送至栈顶 |
| 0x34 | caload | 将 char 型数组指定索引的值推送至栈顶 |
| 0x35 | saload | 将 short 型数组指定索引的值推送至栈顶 |
| 0x36 | istore | 将栈顶 int 型数值存入指定本地变量 |
| 0x37 | lstore | 将栈顶 long 型数值存入指定本地变量 |
| 0x38 | fstore | 将栈顶 float 型数值存入指定本地变量 |
| 0x39 | dstore | 将栈顶 do le 型数值存入指定本地变量 |
| 0x3a | astore | 将栈顶引用型数值存入指定本地变量 |
| 0x3b | istore_0 | 将栈顶 int 型数值存入第一个本地变量 |
| 0x3c | istore_1 | 将栈顶 int 型数值存入第二个本地变量 |
| 0x3d | istore_2 | 将栈顶 int 型数值存入第三个本地变量 |
| 0x3e | istore_3 | 将栈顶 int 型数值存入第四个本地变量 |
| 0x3f | lstore_0 | 将栈顶 long 型数值存入第一个本地变量 |
| 0x40 | lstore_1 | 将栈顶 long 型数值存入第二个本地变量 |
| 0x41 | lstore_2 | 将栈顶 long 型数值存入第三个本地变量 |
| 0x42 | lstore_3 | 将栈顶 long 型数值存入第四个本地变量 |
| 0x43 | fstore_0 | 将栈顶 float 型数值存入第一个本地变量 |
| 0x44 | fstore_1 | 将栈顶 float 型数值存入第二个本地变量 |
| 0x45 | fstore_2 | 将栈顶 float 型数值存入第三个本地变量 |
| 0x46 | fstore_3 | 将栈顶 float 型数值存入第四个本地变量 |
| 0x47 | dstore_0 | 将栈顶 do le 型数值存入第一个本地变量 |
| 0x48 | dstore_1 | 将栈顶 do le 型数值存入第二个本地变量 |
| 0x49 | dstore_2 | 将栈顶 do le 型数值存入第三个本地变量 |
| 0x4a | dstore_3 | 将栈顶 do le 型数值存入第四个本地变量 |
| 0x4b | astore_0 | 将栈顶引用型数值存入第一个本地变量 |
| 0x4c | astore_1 | 将栈顶引用型数值存入第二个本地变量 |
| 0x4d | astore_2 | 将栈顶引用型数值存入第三个本地变量 |
| 0x4e | astore_3 | 将栈顶引用型数值存入第四个本地变量 |
| 0x4f | iastore | 将栈顶 int 型数值存入指定数组的指定索引位置 |
| 0x50 | lastore | 将栈顶 long 型数值存入指定数组的指定索引位置 |
| 0x51 | fastore | 将栈顶 float 型数值存入指定数组的指定索引位置 |
| 0x52 | dastore | 将栈顶 do le 型数值存入指定数组的指定索引位置 |
| 0x53 | aastore | 将栈顶引用型数值存入指定数组的指定索引位置 |
| 0x54 | bastore | 将栈顶 boolean 或 byte 型数值存入指定数组的指定索引位置 |
| 0x55 | castore | 将栈顶 char 型数值存入指定数组的指定索引位置 |
| 0x56 | sastore | 将栈顶 short 型数值存入指定数组的指定索引位置 |
| 0x57 | pop | 将栈顶数值弹出 (数值不能是 long 或 do le 类型的) |
| 0x58 | pop2 | 将栈顶的一个(long 或 do le 类型的) 或两个数值弹出(其它) |
| 0x59 | dup | 复制栈顶数值并将复制值压入栈顶 |
| 0x5a | dup_x1 | 复制栈顶数值并将两个复制值压入栈顶 |
| 0x5b | dup_x2 | 复制栈顶数值并将三个(或两个)复制值压入栈顶 |
| 0x5c | dup2 | 复制栈顶一个(long 或 do le 类型的) 或两个(其它)数值并将复制值压入栈顶 |
| 0x5d | dup2_x1 | dup_x1 指令的双倍版本 |
| 0x5e | dup2_x2 | dup_x2 指令的双倍版本 |
| 0x5f | swap | 将栈最顶端的两个数值互换 (数值不能是 long 或 do le 类型的) |
| 0x60 | iadd | 将栈顶两 int 型数值相加并将结果压入栈顶 |
| 0x61 | ladd | 将栈顶两 long 型数值相加并将结果压入栈顶 |
| 0x62 | fadd | 将栈顶两 float 型数值相加并将结果压入栈顶 |
| 0x63 | dadd | 将栈顶两 do le 型数值相加并将结果压入栈顶 |
| 0x64 | is | 将栈顶两 int 型数值相减并将结果压入栈顶 |
| 0x65 | ls | 将栈顶两 long 型数值相减并将结果压入栈顶 |
| 0x66 | fs | 将栈顶两 float 型数值相减并将结果压入栈顶 |
| 0x67 | ds | 将栈顶两 do le 型数值相减并将结果压入栈顶 |
| 0x68 | imul | 将栈顶两 int 型数值相乘并将结果压入栈顶 |
| 0x69 | lmul | 将栈顶两 long 型数值相乘并将结果压入栈顶 |
| 0x6a | fmul | 将栈顶两 float 型数值相乘并将结果压入栈顶 |
| 0x6b | dmul | 将栈顶两 do le 型数值相乘并将结果压入栈顶 |
| 0x6c | idiv | 将栈顶两 int 型数值相除并将结果压入栈顶 |
| 0x6d | ldiv | 将栈顶两 long 型数值相除并将结果压入栈顶 |
| 0x6e | fdiv | 将栈顶两 float 型数值相除并将结果压入栈顶 |
| 0x6f | ddiv | 将栈顶两 do le 型数值相除并将结果压入栈顶 |
| 0x70 | irem | 将栈顶两 int 型数值作取模运算并将结果压入栈顶 |
| 0x71 | lrem | 将栈顶两 long 型数值作取模运算并将结果压入栈顶 |
| 0x72 | frem | 将栈顶两 float 型数值作取模运算并将结果压入栈顶 |
| 0x73 | drem | 将栈顶两 do le 型数值作取模运算并将结果压入栈顶 |
| 0x74 | ineg | 将栈顶 int 型数值取负并将结果压入栈顶 |
| 0x75 | lneg | 将栈顶 long 型数值取负并将结果压入栈顶 |
| 0x76 | fneg | 将栈顶 float 型数值取负并将结果压入栈顶 |
| 0x77 | dneg | 将栈顶 do le 型数值取负并将结果压入栈顶 |
| 0x78 | ishl | 将 int 型数值左移位指定位数并将结果压入栈顶 |
| 0x79 | lshl | 将 long 型数值左移位指定位数并将结果压入栈顶 |
| 0x7a | ishr | 将 int 型数值右(符号)移位指定位数并将结果压入栈顶 |
| 0x7b | lshr | 将 long 型数值右(符号)移位指定位数并将结果压入栈顶 |
| 0x7c | iushr | 将 int 型数值右(无符号)移位指定位数并将结果压入栈顶 |
| 0x7d | lushr | 将 long 型数值右(无符号)移位指定位数并将结果压入栈顶 |
| 0x7e | iand | 将栈顶两 int 型数值作 “按位与” 并将结果压入栈顶 |
| 0x7f | land | 将栈顶两 long 型数值作 “按位与” 并将结果压入栈顶 |
| 0x80 | ior | 将栈顶两 int 型数值作 “按位或” 并将结果压入栈顶 |
| 0x81 | lor | 将栈顶两 long 型数值作 “按位或” 并将结果压入栈顶 |
| 0x82 | ixor | 将栈顶两 int 型数值作 “按位异或” 并将结果压入栈顶 |
| 0x83 | lxor | 将栈顶两 long 型数值作 “按位异或” 并将结果压入栈顶 |
| 0x84 | iinc | 将指定 int 型变量增加指定值(i++, i–, i+=2) |
| 0x85 | i2l | 将栈顶 int 型数值强制转换成 long 型数值并将结果压入栈顶 |
| 0x86 | i2f | 将栈顶 int 型数值强制转换成 float 型数值并将结果压入栈顶 |
| 0x87 | i2d | 将栈顶 int 型数值强制转换成 do le 型数值并将结果压入栈顶 |
| 0x88 | l2i | 将栈顶 long 型数值强制转换成 int 型数值并将结果压入栈顶 |
| 0x89 | l2f | 将栈顶 long 型数值强制转换成 float 型数值并将结果压入栈顶 |
| 0x8a | l2d | 将栈顶 long 型数值强制转换成 do le 型数值并将结果压入栈顶 |
| 0x8b | f2i | 将栈顶 float 型数值强制转换成 int 型数值并将结果压入栈顶 |
| 0x8c | f2l | 将栈顶 float 型数值强制转换成 long 型数值并将结果压入栈顶 |
| 0x8d | f2d | 将栈顶 float 型数值强制转换成 do le 型数值并将结果压入栈顶 |
| 0x8e | d2i | 将栈顶 do le 型数值强制转换成 int 型数值并将结果压入栈顶 |
| 0x8f | d2l | 将栈顶 do le 型数值强制转换成 long 型数值并将结果压入栈顶 |
| 0x90 | d2f | 将栈顶 do le 型数值强制转换成 float 型数值并将结果压入栈顶 |
| 0x91 | i2b | 将栈顶 int 型数值强制转换成 byte 型数值并将结果压入栈顶 |
| 0x92 | i2c | 将栈顶 int 型数值强制转换成 char 型数值并将结果压入栈顶 |
| 0x93 | i2s | 将栈顶 int 型数值强制转换成 short 型数值并将结果压入栈顶 |
| 0x94 | lcmp | 比较栈顶两 long 型数值大小,并将结果(1,0,-1)压入栈顶 |
| 0x95 | fcmpl | 比较栈顶两 float 型数值大小,并将结果(1,0,-1)压入栈顶;当其中一个数值为 NaN 时,将 - 1 压入栈顶 |
| 0x96 | fcmpg | 比较栈顶两 float 型数值大小,并将结果(1,0,-1)压入栈顶;当其中一个数值为 NaN 时,将 1 压入栈顶 |
| 0x97 | dcmpl | 比较栈顶两 do le 型数值大小,并将结果(1,0,-1)压入栈顶;当其中一个数值为 NaN 时,将 - 1 压入栈顶 |
| 0x98 | dcmpg | 比较栈顶两 do le 型数值大小,并将结果(1,0,-1)压入栈顶;当其中一个数值为 NaN 时,将 1 压入栈顶 |
| 0x99 | ifeq | 当栈顶 int 型数值等于 0 时跳转 |
| 0x9a | ifne | 当栈顶 int 型数值不等于 0 时跳转 |
| 0x9b | iflt | 当栈顶 int 型数值小于 0 时跳转 |
| 0x9c | ifge | 当栈顶 int 型数值大于等于 0 时跳转 |
| 0x9d | ifgt | 当栈顶 int 型数值大于 0 时跳转 |
| 0x9e | ifle | 当栈顶 int 型数值小于等于 0 时跳转 |
| 0x9f | if_icmpeq | 比较栈顶两 int 型数值大小,当结果等于 0 时跳转 |
| 0xa0 | if_icmpne | 比较栈顶两 int 型数值大小,当结果不等于 0 时跳转 |
| 0xa1 | if_icmplt | 比较栈顶两 int 型数值大小,当结果小于 0 时跳转 |
| 0xa2 | if_icmpge | 比较栈顶两 int 型数值大小,当结果大于等于 0 时跳转 |
| 0xa3 | if_icmpgt | 比较栈顶两 int 型数值大小,当结果大于 0 时跳转 |
| 0xa4 | if_icmple | 比较栈顶两 int 型数值大小,当结果小于等于 0 时跳转 |
| 0xa5 | if_acmpeq | 比较栈顶两引用型数值,当结果相等时跳转 |
| 0xa6 | if_acmpne | 比较栈顶两引用型数值,当结果不相等时跳转 |
| 0xa7 | goto | 无条件跳转 |
| 0xa8 | jsr | 跳转至指定 16 位 offset 位置,并将 jsr 下一条指令地址压入栈顶 |
| 0xa9 | ret | 返回至本地变量 |
| 0xaa | tableswitch | 用于 switch 条件跳转,case 值连续(可变长度指令) |
| 0xab | lookupswitch | 用于 switch 条件跳转,case 值不连续(可变长度指令) |
| 0xac | ireturn | 从当前方法返回 int |
| 0xad | lreturn | 从当前方法返回 long |
| 0xae | freturn | 从当前方法返回 float |
| 0xaf | dreturn | 从当前方法返回 do le |
| 0xb0 | areturn | 从当前方法返回对象引用 |
| 0xb1 | return | 从当前方法返回 void |
| 0xb2 | getstatic | 获取指定类的静态域,并将其值压入栈顶 |
| 0xb3 | putstatic | 为指定的类的静态域赋值 |
| 0xb4 | getfield | 获取指定类的实例域,并将其值压入栈顶 |
| 0xb5 | putfield | 为指定的类的实例域赋值 |
| 0xb6 | invokevirtual | 调用实例方法 |
| 0xb7 | invokespecial | 调用超类构造方法,实例初始化方法,私有方法 |
| 0xb8 | invokestatic | 调用静态方法 |
| 0xb9 | invokeinterface | 调用接口方法 |
| 0xba | – | 无此指令 |
| 0xbb | new | 创建一个对象,并将其引用值压入栈顶 |
| 0xbc | newarray | 创建一个指定原始类型(如 int, float, char…)的数组,并将其引用值压入栈顶 |
| 0xbd | anewarray | 创建一个引用型(如类,接口,数组)的数组,并将其引用值压入栈顶 |
| 0xbe | arraylength | 获得数组的长度值并压入栈顶 |
| 0xbf | athrow | 将栈顶的异常抛出 |
| 0xc0 | checkcast | 检验类型转换,检验未通过将抛出 ClassCastException |
| 0xc1 | instanceof | 检验对象是否是指定的类的实例,如果是将 1 压入栈顶,否则将 0 压入栈顶 |
| 0xc2 | monitorenter | 获得对象的锁,用于同步方法或同步块 |
| 0xc3 | monitorexit | 释放对象的锁,用于同步方法或同步块 |
| 0xc4 | wide | <待补充> |
| 0xc5 | multianewarray | 创建指定类型和指定维度的多维数组(执行该指令时,操作栈中必须包含各维度的长度值),并将其引用值压入栈顶 |
| 0xc6 | ifnull | 为 null 时跳转 |
| 0xc7 | ifnonnull | 不为 null 时跳转 |
| 0xc8 | goto_w | 无条件跳转(宽索引) |
| 0xc9 | jsr_w | 跳转至指定 32 位 offset 位置,并将 jsr_w 下一条指令地址压入栈顶 |
当然,这么多属性根本不用记住,需要的时候查表就行.
SourceFile 属性,用于记录生成这个class文件的源码文件名称,即附加属性.它的属性结构如下
| 类型 | 名称 | 数量 | 含义 |
|---|---|---|---|
| u2 | attribute_name_index | 1 | 属性名索引 |
| u4 | attribute_length | 1 | 属性长度 |
| u2 | sourcefile_index | 1 | 源码文件索引 |
- 属性名索引的值为
0x000d,即常量池中的第 13 项,查询可得:SourceFile - 属性长度的值为
0x00 00 00 02, 即长度为 2 - 源码文件索引的值为
0x000e, 即常量池中的第 14 项, 查询可得:Hello.java
其他还有一些Java虚拟机预定义了很多属性,就不一一解读了,就是查字典.
- Exception属性:列举出方法中可能抛出的受查异常
- LineNumberTable属性:用于描述Java源码行号与字节码行号(字节码的偏移量)之间的对应关系。它并不是运行时必须的属性,但默认会生成到class文件中。如果选择不生成这个属性,对程序运行产生的最主要影响是当抛出异常时,堆栈中将不会显示出错的行号,并且在调试程序的时候,也无法按照源码行来设置断点。
- LocalVariableTable属性:用于描述栈帧中局部变量表的变量与Java源码中定义的变量之间的关系,它不是运行时必需的属性,但默认会生成到class文件中。如果没有生成这项属性,最大的影响就是当其他人引用这个方法时,所有的参数名称都将丢失,比如IDE将会使用arg0、arg1之类的占位符代替原有的参数名,这对程序运行没有影响,但是会对代码编写带来较大不便,而且再调试期间无法根据参数名称从上下文中获得参数值。
- ConstantValue属性的作用是通知虚拟机自动为静态变量赋值。只有被static关键字修饰的变量才可以使用这项属性。虚拟机对普通类型的类变量和static的类变量赋值的方式和时刻都有所不同。对非static类型的变量(即实例变量)
Java字节码就是一些Java虚拟机的指令,而这些指令需要依赖class文件,所以首先得读取class文件内容.而class文件内容就是一些16进制的数据,很紧凑地将数据按顺序摆放在一起,只需要顺序解读,即可得到指令内容.
ps: 就像《深入理解Java虚拟机》一书中所说的那样,解读class其实就是查字典嘛,来嘛,查嘛,慢慢搞嘛,我就不信治不了你. 刚开始的时候读起来特别不舒服,读不太懂这玩意儿,后面慢慢地终于读懂了,再写篇文章详细记录一下,加深现象. 博客写得不是很详细,如果感兴趣,建议还是看书(《深入理解Java虚拟机》第六章)更系统些.
- 一文让你明白Java字节码
- Java字节码 维基百科
- 深入理解JVM 读懂java字节码
- 如何阅读JAVA 字节码(一)
- 从一个class文件深入理解Java字节码结构
- 《深入理解Java虚拟机》第六章