diff --git a/README.md b/README.md
index c13cbe6..7f6f584 100755
--- a/README.md
+++ b/README.md
@@ -40,8 +40,8 @@ I regularly update [my blog in Toward Data Science](https://medium.com/@patrickl
- [OpenVLA: An Open-Source Vision-Language-Action Model](https://arxiv.org/abs/2406.09246) [open source RT-2]
- [Parting with Misconceptions about Learning-based Vehicle Motion Planning](https://arxiv.org/abs/2306.07962) CoRL 2023 [Simple non-learning based baseline]
- [QuAD: Query-based Interpretable Neural Motion Planning for Autonomous Driving](https://arxiv.org/abs/2404.01486) [Waabi]
-- [MPDM: Multipolicy decision-making in dynamic, uncertain environments for autonomous driving](https://ieeexplore.ieee.org/document/7139412) ICRA 2015 [Behavior planning, UMich, May Autonomy]
-- [MPDM2: Multipolicy Decision-Making for Autonomous Driving via Changepoint-based Behavior Prediction](https://www.roboticsproceedings.org/rss11/p43.pdf) RSS 2015 [Behavior planning]
+- [MPDM: Multipolicy decision-making in dynamic, uncertain environments for autonomous driving](https://ieeexplore.ieee.org/document/7139412) [[Notes](paper_notes/mpdm.md)] ICRA 2015 [Behavior planning, UMich, May Autonomy]
+- [MPDM2: Multipolicy Decision-Making for Autonomous Driving via Changepoint-based Behavior Prediction](https://www.roboticsproceedings.org/rss11/p43.pdf) [[Notes](paper_notes/mpdm2.md)] RSS 2015 [Behavior planning]
- [MPDM3: Multipolicy decision-making for autonomous driving via changepoint-based behavior prediction: Theory and experiment](https://link.springer.com/article/10.1007/s10514-017-9619-z) RSS 2017 [Behavior planning]
- [EUDM: Efficient Uncertainty-aware Decision-making for Automated Driving Using Guided Branching](https://arxiv.org/abs/2003.02746) [[Notes](paper_notes/eudm.md)] ICRA 2020 [Wenchao Ding, Shaojie Shen, Behavior planning]
- [TPP: Tree-structured Policy Planning with Learned Behavior Models](https://arxiv.org/abs/2301.11902) ICRA 2023 [Marco Pavone, Nvidia, Behavior planning]
diff --git a/learning_pnc/pnc_notes.md b/learning_pnc/pnc_notes.md
index 0779db2..ad6b8ea 100644
--- a/learning_pnc/pnc_notes.md
+++ b/learning_pnc/pnc_notes.md
@@ -12,7 +12,7 @@
- Model-inspired leanring methods
- Planning of ego for next 8-10s. Need to do prediction.
- Prediction KPI
- - recall and precision on instance/event level, and their tradeoff. 误抢,误让
+ - recall and precision on instance/event level, and their tradeoff. 误抢,误让,误绕
- ADE and FDE not good metrics.
- The tradeoff typically calls for a hybrid system model, learning vs model-based.
- Interaction: multimodality and uncertainty
@@ -29,7 +29,7 @@
- scenarios
- Agent to map, agent to agent interaction.
-# Constant velocity
+## Constant velocity
- System evolution
- 1st: CV and CT, baseline for fallback
@@ -106,6 +106,7 @@
# Path and Trajectory planning
- 路径轨迹规划三板斧:搜索,采样,优化. Typical planning methods, search, sampling, optimization)
+- PNC三大目标:安全,舒适,高效 (safety, comfort and efficiency)
- trajectory = path + speed
## Search
@@ -129,7 +130,7 @@
- Need N discrete control action, e.g., discrete curvature.
- Pruning: Multiple action history may lead to the same grid. Need pruning of action history to keep the lowest cost one.
- Early stopping (analytical expansion, shot to goal): This is another key innovation in hybrid A-star. The analogy in A-star search algorithm is if we can connect the last popped node to the goal using a non-colliding straight line, we have found the solution. In hybrid A-star, the straight line is replaced by Dubins and RS (Reeds Shepp) curves. Maybe suboptimal but it focuses more on the feasibility on the further side. (近端要求最优性,远端要求可行性。)
- - Hybrid A-star: Path Planning for Autonomous Vehicles in Unknown Semi-structured Environments IJRR 2010 [Dolgov, Thrun, Searching]
+ - [Hybrid A-star: Path Planning for Autonomous Vehicles in Unknown Semi-structured Environments](https://www.semanticscholar.org/paper/Path-Planning-for-Autonomous-Vehicles-in-Unknown-Dolgov-Thrun/0e8c927d9c2c46b87816a0f8b7b8b17ed1263e9c) IJRR 2010 [Dolgov, Thrun, Searching]
- Dubins and RS curves
- Dubins is essentially (arch-line-arch). RS curve improves Dubins curve by adding reverse motion.
- Holonomic vs non-holonomic (完整约束和非完整约束)
@@ -162,7 +163,7 @@
- actually 5th polynomial (wrt time, not y wrt x!) is the optimal solution to a much more broader range of control problem.
- Optimization by sampling. If we already know 5th polynomial is optimal, we can sample in this space and find the one with min cost to get the approximate solution.
- Speed scenarios
- - High speed traj (5-6 m/s+): lateral s(t) and longitudinal d(t) can be treated as decoupled, and can be calculated independently.
+ - High speed traj (5-6 m/s+): lateral d(t) and longitudinal s(t) (station) can be treated as decoupled, and can be calculated independently.
- Low speed traj: lateral and longitudinal are tightly coupled, and bounded by kinematics. If sampled independently, curvature may not be physically possible. Remedy: focus on s(t) and d(s(t)).
- Eval and check after sampling
- Selection based on min Cost
@@ -295,13 +296,13 @@
# Decision Making
## Markov Decision Process
-
- Why do we need decision making since we have planning already?
- keywords: interaction and uncertainty. This makes the world probabilistic. Mainly from dynamic objects. —> **Interaction is actually the most difficult part of autonomous driving**, making it harder than robotics. It is like playing a game with probabilistic world model.
- - If the world is deterministic (geometry), there is no decision making needed. Searching, sampling, and optimization should be good enough.
+ - If the world is deterministic (geometry), there is no decision making needed, and planning itself (searching, sampling, and optimization) should be good enough.
- For stochastic strategy, then MDP or POMDP.
- - Like RL, need to understand the entire problem setting to design S, A, R, and E.
+ - Like RL, need to understand the entire problem setting to design S, A, R, and E. Need to understand the problem and then design RL system.
- To do e2e, we need to understand the decision making system first.
+ - The problem with prediction-then-plan: the world is deterministic, this will lead to reckless behavior. Prediction actually has motion-level and even intent-level uncertainty.
- Does it mean that for dynamic objects we must need decision? Not necessarily. Consider objects moving on known rails with constant known speed (or if we treat multimodal prediction as certainty hard constraint), then pure planning methods can solve it and we do not need decision making at all.
- Every decision is a bunch/cluster of planning.
- “Freezing robot”: prediction fills the entire S-T. 华山挤出一条路。Geometry —> Probability to the rescue.
@@ -333,7 +334,7 @@
- Value iteration as the vanilla approach and gives the feasibility (like Dijkstra) but typically not useful in practice.
- Reward is typically certain, but discount factor (far-sighted or short-sighted) and uncertainty would affect policy severely.
- Value iteration to optimal policy: Use the optimal value function to determine the best action in each state, thereby obtaining the optimal policy. A policy spells out an action (or probability distribution) given a state, pi(s) = a.
- - $\pi^*(s) = \arg \max_a \left[R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) V^*(s')\right]$
+ - $\pi^*(s) = \arg \max_a \left[R(s,a) + \gamma \sum_{s'} P(s' \mid s,a) V^*(s')\right]$
- Policy iteration (the improved version)
- Value iteration requires to take the optimal action at each iteration. Policy iteration decouples policy evaluation and policy improvement. (每天进步一点点。)
- Policy evaluation evaluates V^pi, basically V based on policy (without max a! This is faster). Any initial policy would do. This is an iterative step, but faster as each step is taken based on a given policy instead of exploring all possible actions (max a).
@@ -575,4 +576,4 @@
- Hybrid system with data-driven and physics-based checks.
- My takeaways:
- Most people would argue that ML should be applied to high level decision making, but Tesla actually used ML in the most fundamental way to accelerate optimization and thus tree search.
- - The MCTS methods seems to be the ultimate tool to decision making. It seems that people studying LLM are trying to get MCTS into LLM, but people working on AD are trying to get rid of MCTS for LLM.
\ No newline at end of file
+ - The MCTS methods seems to be the ultimate tool to decision making. It seems that people studying LLM are trying to get MCTS into LLM, but people working on AD are trying to get rid of MCTS for LLM.
diff --git a/paper_notes/mpdm2.md b/paper_notes/mpdm2.md
new file mode 100644
index 0000000..b9dddf5
--- /dev/null
+++ b/paper_notes/mpdm2.md
@@ -0,0 +1,29 @@
+# [MPDM2: Multipolicy Decision-Making for Autonomous Driving via Changepoint-based Behavior Prediction](https://www.roboticsproceedings.org/rss11/p43.pdf)
+
+_June 2024_
+
+tl;dr: Improvement of MPDM in predicting the intention of other vehicles.
+
+#### Overall impression
+The majority is the same as the previous work [MPDM](mpdm.md).
+
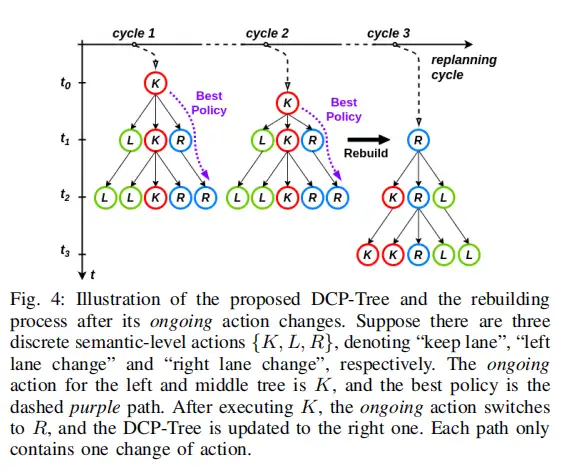
+For the policy tree (or policy-conditioned scenario tree) building, we can see how the tree got built with more and more careful pruning process with improvements from different works.
+
+* [MPDM](mpdm.md) iterates over all ego policies, and uses the most likely one policy given road structure and pose of vehicle.
+* [MPDM2](mpdm2.md) iterates over all ego policies, and iterate over (a set of) possible policies of other agents predicted by a motion prediction model.
+* [EUDM](eudm.md) itrates all ego policies, and then iterate over all possible policies of other agents to identify **critical scenarios** (CFB, conditioned filtered branching). [EPSILON](epsilon.md) used the same method.
+* [MARC](marc.md) iterates all ego policies, iterates over a set of predicted policies of other agents, identifies **key agents** (and ignores other agents even in critical scenarios).
+
+
+
+
+
+#### Key ideas
+- Motion prediction of other agents with a classical ML methods (Maximum likelihood estimation).
+
+#### Technical details
+- Summary of technical details, such as important training details, or bugs of previous benchmarks.
+
+#### Notes
+- Questions and notes on how to improve/revise the current work
+