| layout | title | nav_order | description | permalink |
|---|---|---|---|---|
default |
Getting Started |
2 |
... |
/getting-started/ |
{: .no_toc }
Table of contents
{: .text-delta } 1. TOC {:toc}{: .d-inline-block }
The following guide assumes that the user/maintainer has a basic understanding of AWS (particularly S3 buckets), Python and some basic HTML. However, do not worry in case you have never used them before, we will guide you through and illustrate below where and how each component comes into play.
To download papertool on your local machine, run:
git clone https://github.com/sodalabsio/papertool.git
Alternatively, you could also fork the repository to your personal github account and work from there.
Before starting with PaperTool, you will need valid three-letter RePEc Archive code (aaa) and a six-letter Series code (ssssss) associated with your working paper series. Please check out the RePEc step-by-step for the same.
You should also have created a cover.png file to serve as your working paper series cover page template. PaperTool will automatically add the working paper meta-data to this template, using the middle portion of the page. It is essential that the template is of the same dimensions as the one provided in the s3_buckets/working_papers_bucket/template/cover.png file (i.e. 2487 x 3516 px). Review the existing cover.png file to understand the layout. The section in the middle is where the working paper meta-data will be added. When you are happy with your cover page template, replace the existing aws_resources/s3_buckets/working_papers_bucket/cover.png file with your own.
By default PaperTool runs from public buckets on your S3. RePEc requires your archive bucket to have public read access (s3:GetObject) since this bucket is allowing RePEc to index your papers, and to point the world to your working paper files for download. However, in the initial installation, the archive bucket also allows write access publicly (s3:PutObject), since we need to allow the PaperTool functions to write new index files and pdfs to this folder. However, this also allows anyone on the internet to write to this bucket. By default, permissions for the site bucket are the same, read/write access is public. As such, we strongly recommend you edit the bucket policy for each bucket to reduce this risk surface.
Now, there are a variety of ways that you may want to limit access on your PaperTool buckets, and so we leave this to your own AWS security policies and risk appetite. One example approach is to allow public read access for both buckets (since RePEc needs it for the archive, and your users will need to access the upload site), but restrict write access to the archive only to an AWS role associated with the Lambda function. You can also ensure that not just anyone can use the PaperTool upload site by adding IP address restrictions to the API Gateway. In this scenario your users will need to be on a specific network to successfully use PaperTool, but this could include a university VPN so that they can still upload from home. For more information please refer to the AWS documentation.
Once you have papertool on your machine, you will see the following main folders/files:
./papertool
├── aws_resources
| ├── cloudformation_templates
| | ├── CreateLambdaAPI.yaml
| | └── CreateS3Buckets.yaml
| └── s3_buckets
| ├── code_bucket
| ├── site_bucket
| └── working_papers_bucket
...- Log in or create your AWS account
- Once you have access to the AWS Console, launch the CloudFormation service. Then:
- Step 1: Create stack
- Click on the
Create Stack- Choose
With new resources (standard)if you are using the CloudFormation > Stacks menu
- Choose
- Under
Prerequisite - Prepare templateselectChoose an existing template - Under
Specify templateselectUpload a template fileand uploadCreateS3Buckets.yamlfile.
 - Click `Next`
- Click `Next`
- Click on the
- Step 2: Specify stack details
- Under
Provide a stack nameenter the name of the stack (any name of your choosing) (e.g.PaperTool) - Under
Parametersplease enter your working paper series details (such as RePEc codes for the series and archive). Important: Please assign the name of this bucket as per your lab/department name. E.g. If you set the bucket name asecondept, it will create a site underhttp://econdept.s3-website-ap-southeast-2.amazonaws.com/(for theap-southeast-2region, your region may differ). - Click
Next
- Under
- Step 3: Configure stack options
- Add Tags, and Permissions if required
- Under
Stack failure optionsselectDelete all newly created resources(second section). This is to ensure that in case of any error, the resources are deleted automatically. - Click
Next
- Step 4: Review and create
- Review and finally click on
Submit - Your Stacks list will show the newly created stack as
CREATE_IN_PROGRESS. Wait until theStatusshowsCREATE_COMPLETE
- Review and finally click on
- Step 1: Create stack
-
Navigate to S3 and into your
CodeBucket(Note: You can also directly access the created buckets fromResourcesunder the Stack. The name of the bucket will be the one you entered earlier along with the suffix"-code") -
Once you are inside the S3
CodeBucket, upload (or drag-and-drop) the contents froms3_buckets/code_bucket/. The files are:layer.zipuploadWorkingPaper.zip
-
Now once again under CloudFormation, create a new stack by repeating all the process from above and uploading
CreateLambdaAPI.yamlas the template this time.
- Name the stack as you like, you might like to repeat the name from the previous stack, adding
-lambdato the end - Note: on Step 3: Configure stack options, at the very bottom, make sure to click on "I acknowledge that AWS CloudFormation might create IAM resources" before hitting
Create Stack - Once again, wait until the
StatusshowsCREATE_COMPLETEon your Stacks list
- Editing site bucket:
- Once again in CloudFormation, select the Lambda stack you just created (step 5), and navigate to the
Outputstab on the right hand side of the page. You may need to expand the size of your window to see this tab.

- Editing working papers bucket:
- Rename the
aaaandssssssfolders to yourArchiveCodeandSeriesCoderespectively - Replace "aaa" in both
aaaarch.rdfandaaaseri.rdfwith yourArchiveCode - Fill the rdf files with appropriate working paper information. Important: The
URLinaaaarch.rdfshould be theRePEcArchiveURLas it links your archive to RePEc - Open
RePEc/aaa/index.htmland replace ssssss with yourSeriesCodeand the names of redif files - Replace
s3_buckets/working_papers_bucket/template/cover.pngwith your own template. Important: The template should be identical in dimensions (2487 x 3516 px) and layout. - Finally copy the contents of
s3_buckets/working_papers_bucket/to your actual S3WorkingPapersBucket
- And that's it! You can now start uploading working papers on your site by accessing your PaperTool website. The URL will be made from your siteBucket name, and your region, like this:
http://[siteBucket].s3-website-[region].amazonaws.com/. For example, if your siteBucket is namedecondeptand you are in theap-southeast-2region, your URL will behttp://econdept.s3-website-ap-southeast-2.amazonaws.com/
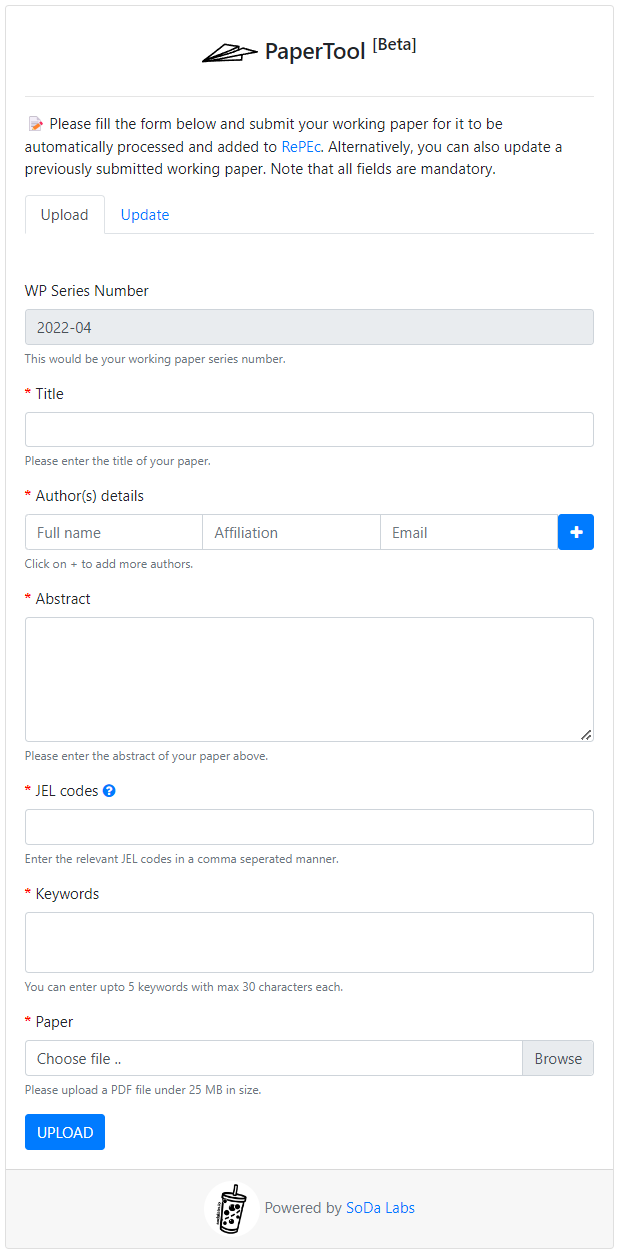
Incase you have any questions please refer to our FAQ page.