This project is a extremely complete implementation of paper 《Pre-release Prediction of Crowd Opinion on Movies by Label Distribution Learning. IJCAI. 2015》.
All training and testing Data are crawled from IMDb.com, reference to ldsvr/oldmoviecrawler.py and ldsvr/newmoviecrawler.py for details.
How can I crawl movie data from IMDb? Just reference to:
Having training movies and testing movies, we need to process and select features from these data, as the paper said.
Reference to ldsvr/features_counting.py, ldsvr/features_indexing.py, ldsvr/matrix_persistent.py, ldsvr/test_matrix.py and ldsvr/training_matrix.py for details. And I use Redis DB for convenient feature counting and processing.
This process can form training matrix and testing matrix for LDSVR Algorithm.
Following the algorithm from paper, I use LDSVR Algorithm to train the model. Please reference to ldsvr/ldsvr.py and paper for details.
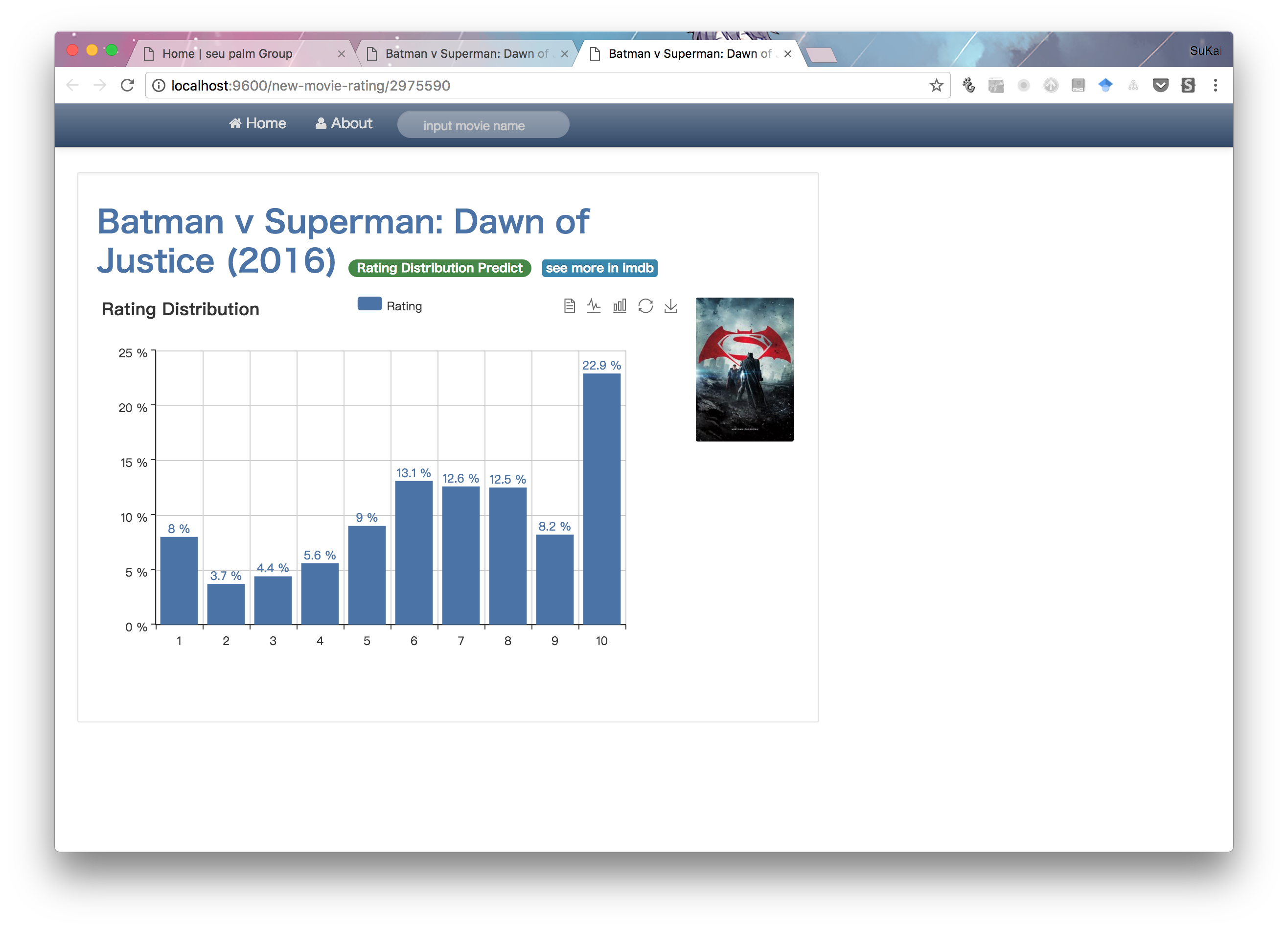
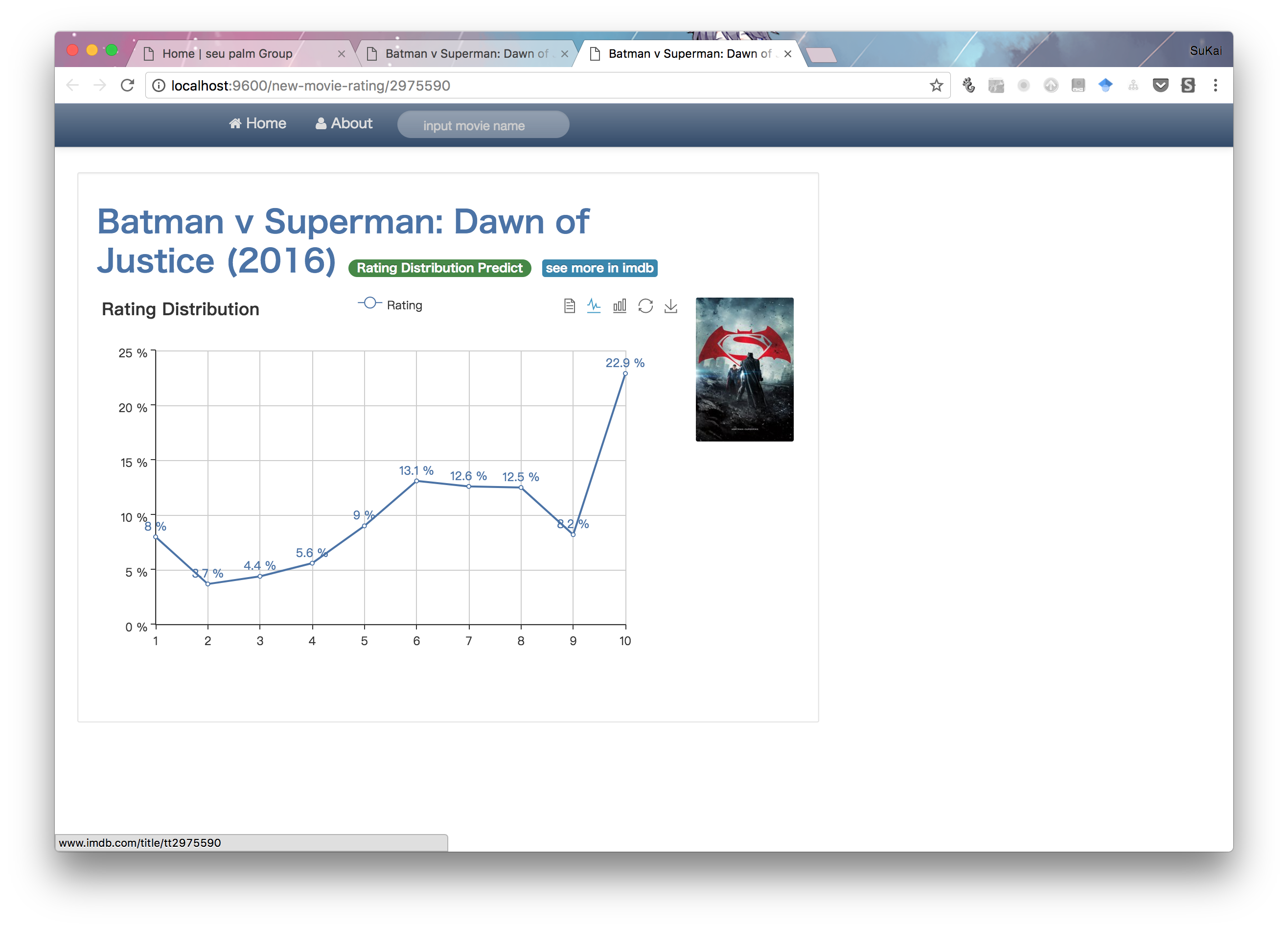
I use Tornado to show results. Here are some website snapshots shown below. And the website need mysql DB for data support.