This application performs real-time object detection on images and videos using the DETR (DEtection TRansformer) model from HuggingFace Transformers.
The DETR model is a transformer-based object detector that eliminates the need for many hand-designed components like NMS.
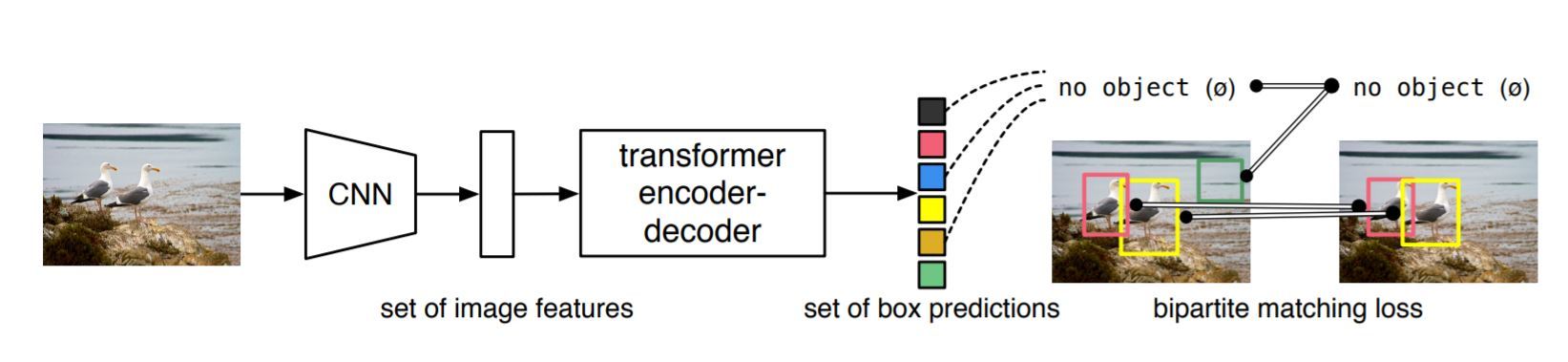
The DETR model follows an encoder-decoder architecture:
- Encoder - A CNN backbone (e.g. ResNet-50) that extracts features from the input image
- Decoder - A transformer model that sequentially predicts objects and their coordinates in the image
The encoder output is flattened and passed to the decoder along with learned object queries. The transformer decoder then works to associate each object query with an object in the image by predicting the bounding box coordinates and classification label.
This overall architecture allows DETR to be trained end-to-end instead of relying on a complex pipeline of multiple stages.
DETR is trained using a bipartite matching loss that matches the predicted and ground truth objects without relying on NMS. The loss function contains:
- Hungarian matching loss to match predictions to GT
- Bounding box loss (L1) between matched boxes
- Classification loss (cross entropy)
These losses allow end-to-end training of the model directly on bounding box annotations.
Some key strengths of DETR:
- Achieves strong object detection performance comparable to Faster R-CNN
- Avoids NMS post-processing step
- Modular components make architecture very flexible
- Parallel decoding step enables fast inference
The DETR model provides an elegant transformer-based implementation for object detection.
The application has the following key components:
-
FastAPI Server - Provides the following endpoints:
/annotate/- Annotate an uploaded image file with detected objects/annotate_video/- Annotate an uploaded video file with detected objects/delete_files/- Delete all temporary files
-
DETR Model - Pretrained DETR model loaded from HuggingFace Transformers
-
Helper Functions - Used for image preprocessing, postprocessing and drawing bounding boxes
-
Async Processing - Allows concurrent processing of multiple image annotation tasks
-
Docker Config - For containerized deployment of the application
To run the app locally:
- Clone the repository
- Install dependencies:
pip install -r requirements.txt - Run:
uvicorn app:fastapi_app --reload - Open
http://localhost:8000/docsfor API docs
Build and run the Docker image:
docker build -t detr-detection .
docker run -p 8080:8080 detr-detectionAlternatively, use docker-compose up to spin up containers.
- Upload image to
/annotate/to detect objects - Upload video to
/annotate_video/to get annotated video - Use
/delete_files/to delete temporary files - Refer API docs for endpoint usage examples
- Lightweight Docker image
- Asynchronous model loading and processing
- Caching recent detections in LFU cache
If you'd like to contribute to this project, please reach out to us at krmohit101@gmail.com . I welcome any improvements to the code or suggestions for new features.!