Being audiophiles, we've always been interested in the kind of effect the 'reading' of music has on its style, and whether there's a quantitative aspect to any tangible reading of music. Thus, we began this project with the thought of understanding how music genres came to be, and whether a stylistic choice can be quantified into a set of features on an image.
For this project, we used the GTZAN Music Genre Dataset. The dataset took the age old GTZAN dataset from 2002 and extended upon it by adding an extracted set of important features in a CSV file, as well as images of the mel-spectrograms of all the audio files, thus making it 3 different datasets for the same purpose. We tried to explore all 3 for the models we made.
./datais the dataset../modelshas all the notebooks used for the different approaches used.
In our first attempt, we made a simple CNN on top of the VGG16 model using Transfer Learning, only to have it give us rather erratic results, either as a result of VGG16 not playing well with the data (it's technically meant for feature extraction from normal images, not graphs), or to do with the data itself.
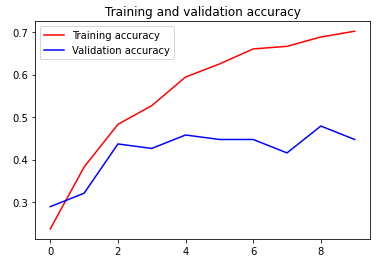
Moving forward, we decided to forgo transfer learning and make a model for scratch. An alternative attempt with the Xception model is possible, and is something we're probably going to implement in the future. Our results using the images was odd, and that strengthened our belief that something was wrong with the image dataset.
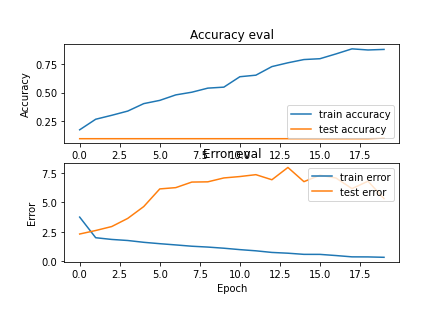
We then took up a more rudimentary approach, using the dataset of 30 second tracks, converting them to mel-spectrograms and feeding the spectrograms into the NN. The results we found were much clearer and commensurate to the kind of performance that other CNN solutions for this problems had been offering all this time.
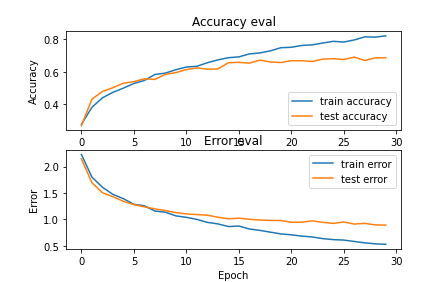
This fetched us an accuracy of 68%, which while being a fair number to stop on, is exactly as much as any CNN solution we found in papers or on the web seemed to have. To push further for better results, we picked up the features CSV file and worked on that. A simple KerasClassifier with standard scaling and KFold cross validation fetched us an accuracy of ~75%, which was markedly higher than all the CNN solutions that we'd explored, while also not being quite overfit to the dataset.
What we learnt was that Genre Classification while being an interesting topic to get into, isn't quite something that can be perfectly quantified using just features, or spectrograms alone. This mostly taught us that it's important for you, the user, to understand the data and its implications on the result before you can expect the model to. We also learnt that GridSearch cross validation is rather convenient.