
Computer Vision and Pattern Recognition is a massive conference. In 2024 alone, 11,532 papers were submitted, and 2,719 were accepted. I created this repository to help you search for crème de la crème of CVPR publications. If the paper you are looking for is not on my short list, take a peek at the full list of accepted papers.
🔥 - highlighted papers
 🔥 SpatialTracker: Tracking Any 2D Pixels in 3D Space
🔥 SpatialTracker: Tracking Any 2D Pixels in 3D Space
Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, Xiaowei Zhou
[paper] [code]
Topic: 3D from multi-view and sensors
Session: Fri 21 Jun 1:30 p.m. EDT — 3 p.m. EDT #84
 ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models
Lukas Höllein, Aljaž Božič, Norman Müller, David Novotny, Hung-Yu Tseng, Christian Richardt, Michael Zollhöfer, Matthias Nießner
[paper] [code] [video]
Topic: 3D from multi-view and sensors
Session: Wed 19 Jun 8 p.m. EDT — 9:30 p.m. EDT #20
OmniGlue: Generalizable Feature Matching with Foundation Model Guidance
Hanwen Jiang, Arjun Karpur, Bingyi Cao, Qixing Huang, Andre Araujo
[paper] [code] [demo]
Topic: 3D from multi-view and sensors
Session: Fri 21 Jun 1:30 p.m. EDT — 3 p.m. EDT #32
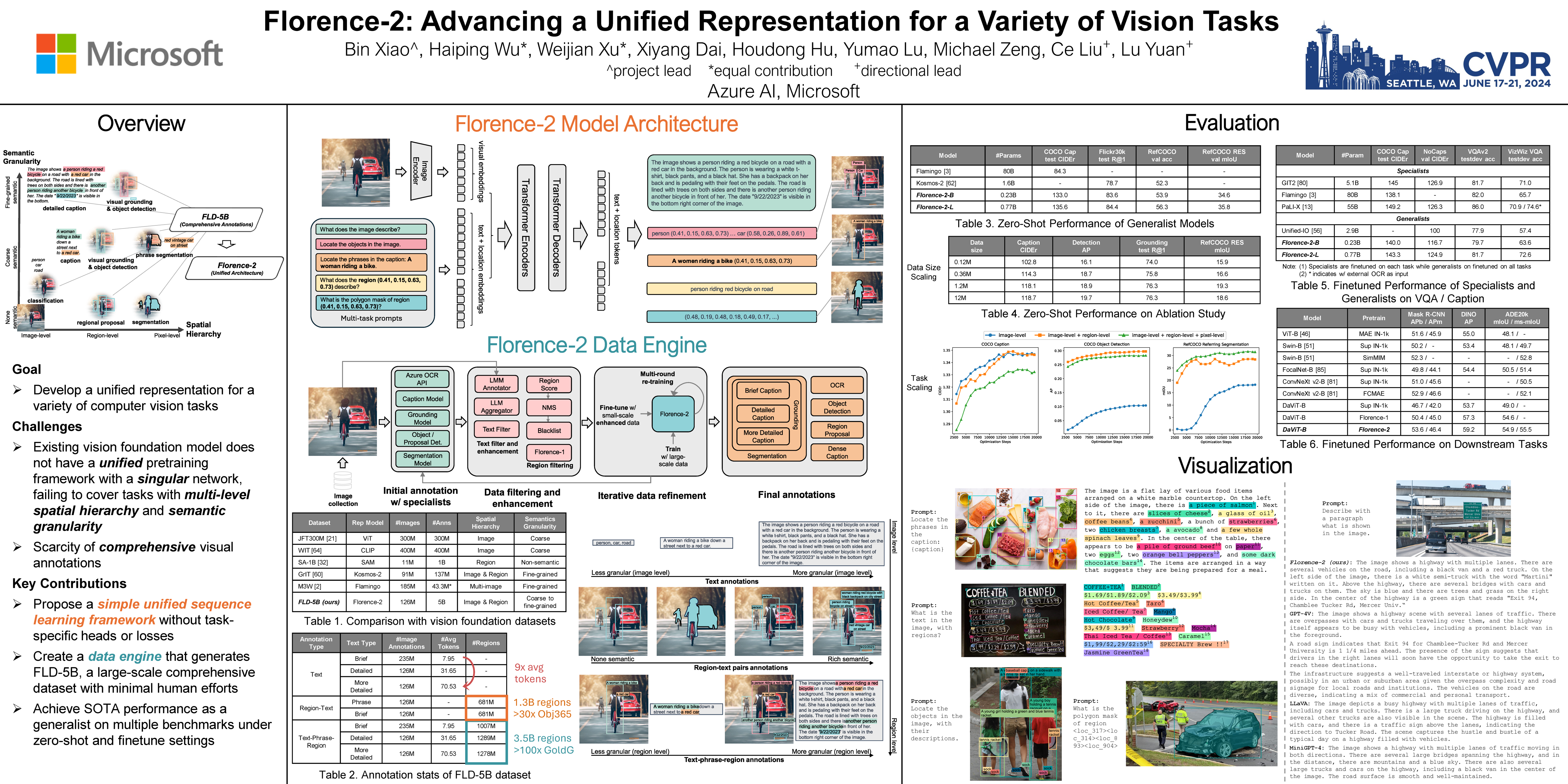 🔥 Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
🔥 Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, Lu Yuan
[paper] [video] [demo] [colab]
Topic: Deep learning architectures and techniques
Session: Wed 19 Jun 8 p.m. EDT — 9:30 p.m. EDT #102
DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks
Jiaxin Zhang, Dezhi Peng, Chongyu Liu, Peirong Zhang, Lianwen Jin
[paper] [code] [demo]
Topic: Document analysis and understanding
Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #101
 🔥 EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
🔥 EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
Yunyang Xiong, Bala Varadarajan, Lemeng Wu, Xiaoyu Xiang, Fanyi Xiao, Chenchen Zhu, Xiaoliang Dai, Dilin Wang, Fei Sun, Forrest Iandola, Raghuraman Krishnamoorthi, Vikas Chandra
[paper] [code] [demo]
Topic: Efficient and scalable vision
Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #144
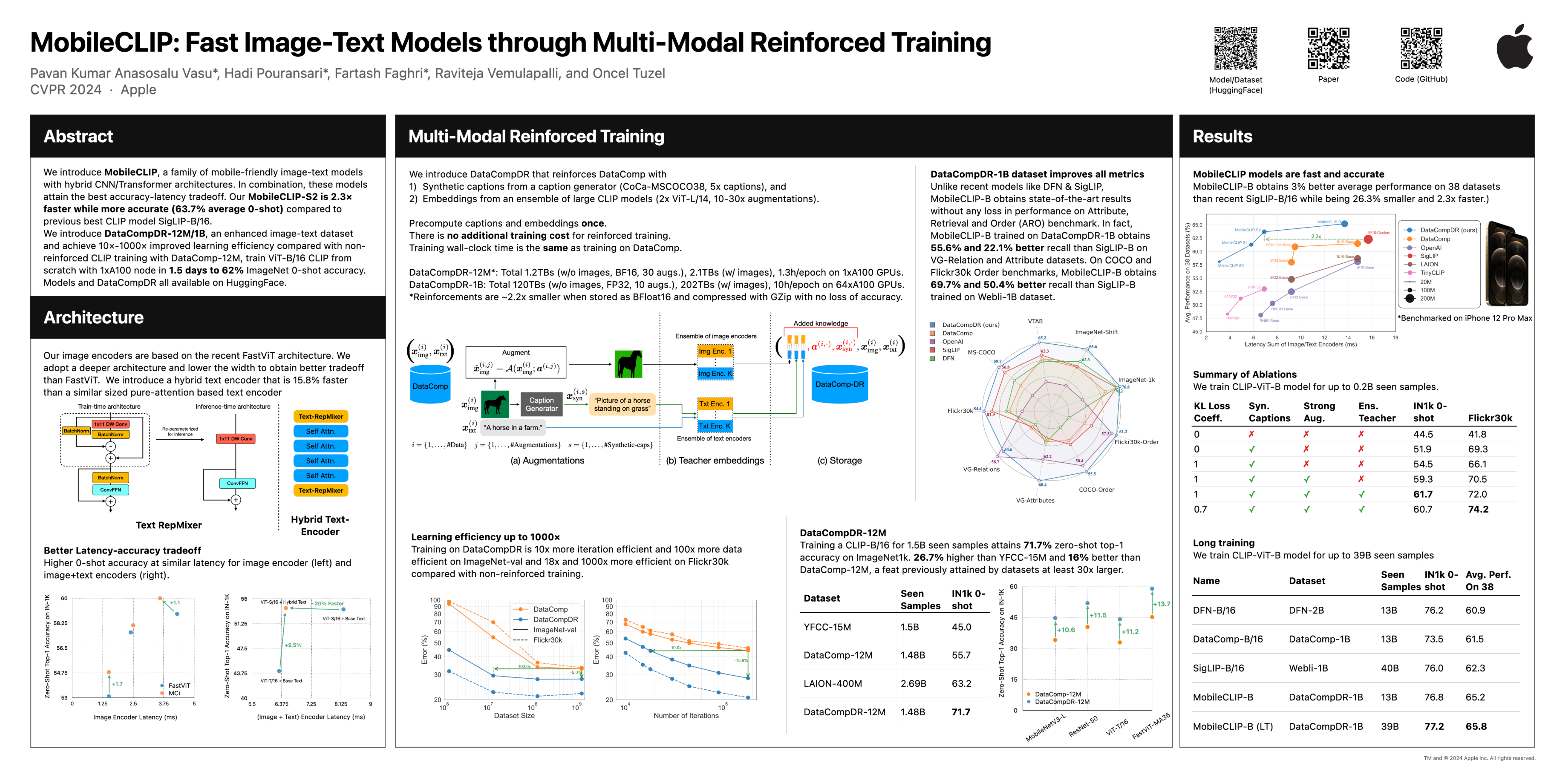
Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel
[paper] [code] [demo]
Topic: Efficient and scalable vision
Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #130
 🔥 Describing Differences in Image Sets with Natural Language
🔥 Describing Differences in Image Sets with Natural Language
Lisa Dunlap, Yuhui Zhang, Xiaohan Wang, Ruiqi Zhong, Trevor Darrell, Jacob Steinhardt, Joseph E. Gonzalez, Serena Yeung-Levy
[paper] [code]
Topic: Explainable computer vision
Session: Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #115
DemoFusion: Democratising High-Resolution Image Generation With No $$$
Ruoyi Du, Dongliang Chang, Timothy Hospedales, Yi-Zhe Song, Zhanyu Ma
[paper] [code] [demo] [colab]
Topic: Image and video synthesis and generation
Session: Wed 19 Jun 8 p.m. EDT — 9:30 p.m. EDT #132
 🔥 DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
🔥 DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
Yujun Shi, Chuhui Xue, Jun Hao Liew, Jiachun Pan, Hanshu Yan, Wenqing Zhang, Vincent Y. F. Tan, Song Bai
[paper] [code] [video]
Topic: Image and video synthesis and generation
Session: Wed 19 Jun 8 p.m. EDT — 9:30 p.m. EDT #392
 🔥 Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models
🔥 Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models
Daniel Geng, Inbum Park, Andrew Owens
[paper] [code] [colab]
Topic: Image and video synthesis and generation
Session: Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #118
 XFeat: Accelerated Features for Lightweight Image Matching
XFeat: Accelerated Features for Lightweight Image Matching
Guilherme Potje, Felipe Cadar, Andre Araujo, Renato Martins, Erickson R. Nascimento
[paper] [code] [video] [demo] [colab]
Topic: Low-level vision
Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #245
 Robust Image Denoising through Adversarial Frequency Mixup
Robust Image Denoising through Adversarial Frequency Mixup
Donghun Ryou, Inju Ha, Hyewon Yoo, Dongwan Kim, Bohyung Han
[paper] [code] [video]
Topic: Low-level vision
Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #250
🔥 Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee
[paper] [code]
Topic: Multi-modal learning
Session: Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #209
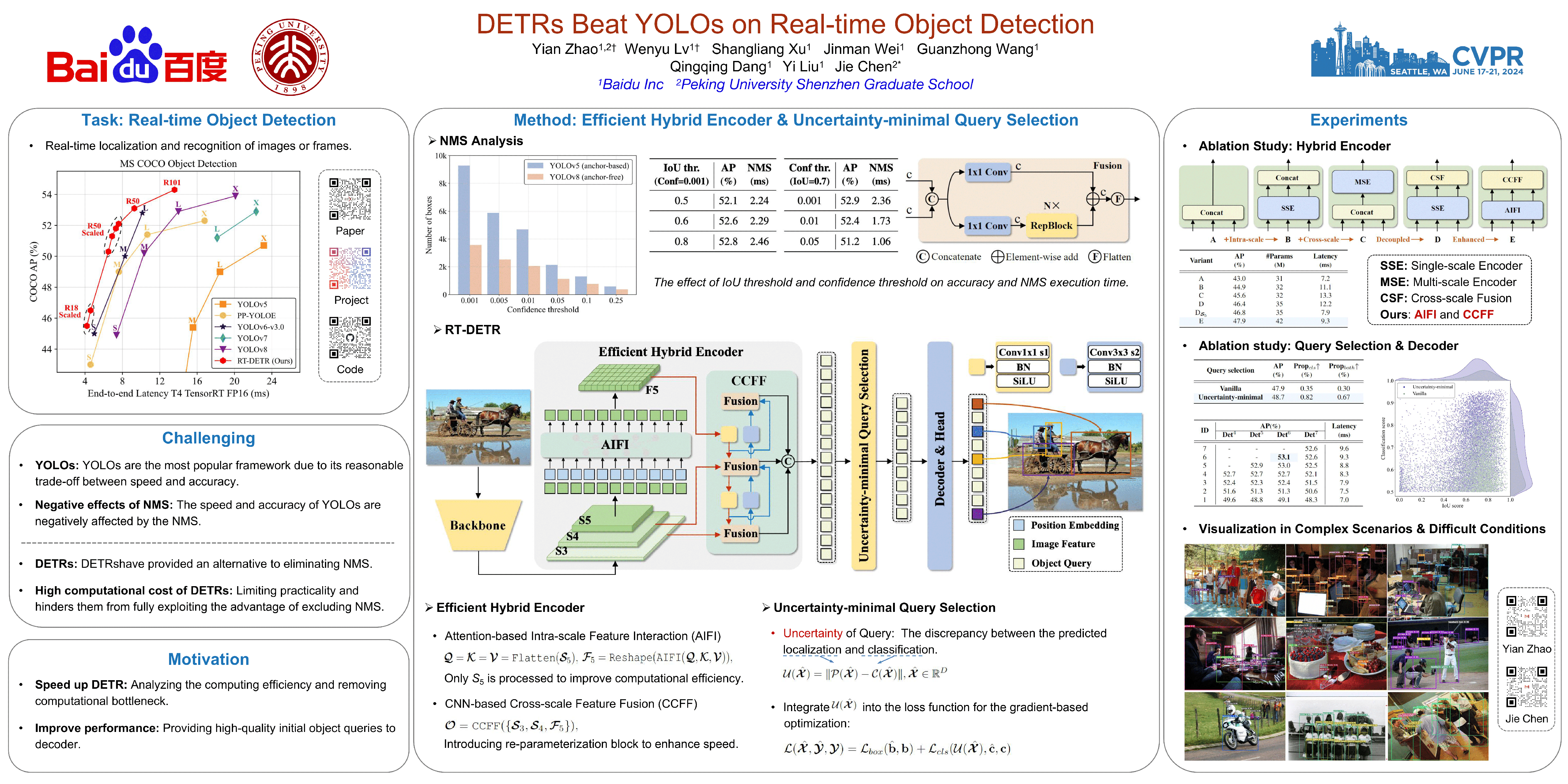 DETRs Beat YOLOs on Real-time Object Detection
DETRs Beat YOLOs on Real-time Object Detection
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen
[paper] [code] [video]
Topic: Recognition: Categorization, detection, retrieval
Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #229
 YOLO-World: Real-Time Open-Vocabulary Object Detection
YOLO-World: Real-Time Open-Vocabulary Object Detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, Ying Shan
[paper] [code] [video] [demo] [colab]
Topic: Recognition: Categorization, detection, retrieval
Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #223
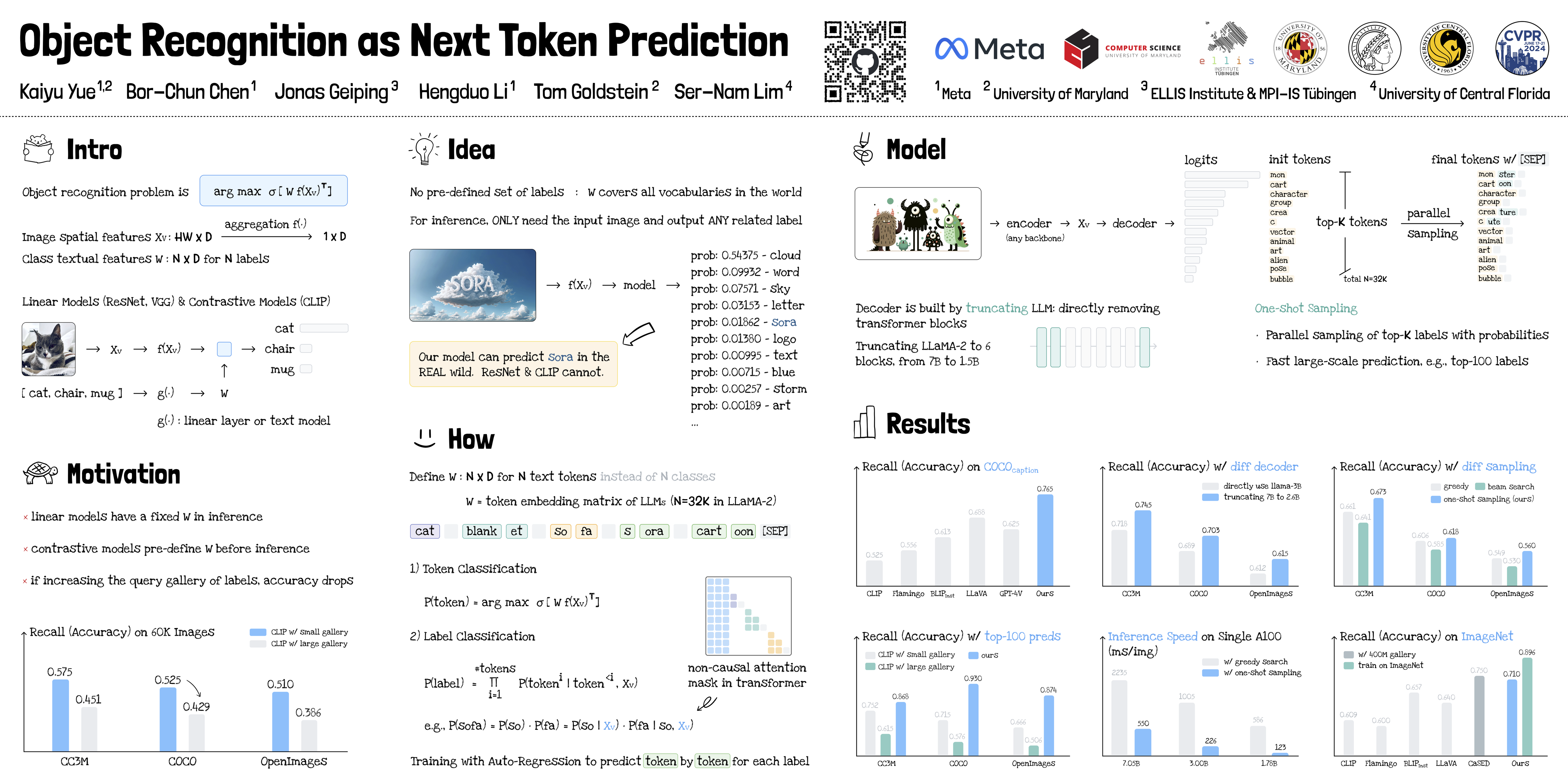 🔥 Object Recognition as Next Token Prediction
🔥 Object Recognition as Next Token Prediction
Kaiyu Yue, Bor-Chun Chen, Jonas Geiping, Hengduo Li, Tom Goldstein, Ser-Nam Lim
[paper] [code] [video] [colab]
Topic: Recognition: Categorization, detection, retrieval
Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #199
 🔥 RobustSAM: Segment Anything Robustly on Degraded Images
🔥 RobustSAM: Segment Anything Robustly on Degraded Images
Wei-Ting Chen, Yu-Jiet Vong, Sy-Yen Kuo, Sizhou Ma, Jian Wang
[paper] [video]
Topic: Segmentation, grouping and shape analysis
Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #378
 🔥 Frozen CLIP: A Strong Backbone for Weakly Supervised Semantic Segmentation
🔥 Frozen CLIP: A Strong Backbone for Weakly Supervised Semantic Segmentation
Bingfeng Zhang, Siyue Yu, Yunchao Wei, Yao Zhao, Jimin Xiao
[paper] [code] [video]
Topic: Segmentation, grouping and shape analysis
Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #351
 🔥 Semantic-aware SAM for Point-Prompted Instance Segmentation
🔥 Semantic-aware SAM for Point-Prompted Instance Segmentation
Zhaoyang Wei, Pengfei Chen, Xuehui Yu, Guorong Li, Jianbin Jiao, Zhenjun Han
[paper] [code] [video]
Topic: Segmentation, grouping and shape analysis
Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #331
🔥 In-Context Matting
He Guo, Zixuan Ye, Zhiguo Cao, Hao Lu
[paper] [code]
Topic: Segmentation, grouping and shape analysis
Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #343
 🔥 General Object Foundation Model for Images and Videos at Scale
🔥 General Object Foundation Model for Images and Videos at Scale
Junfeng Wu, Yi Jiang, Qihao Liu, Zehuan Yuan, Xiang Bai, Song Bai
[paper] [code] [video]
Topic: Segmentation, grouping and shape analysis
Session: Wed 19 Jun 1:30 p.m. EDT — 3 p.m. EDT #350
 🔥 InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
🔥 InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, Jifeng Dai
[paper] [code] [demo]
Topic: Self-supervised or unsupervised representation learning
Session: Fri 21 Jun 8 p.m. EDT — 9:30 p.m. EDT #412
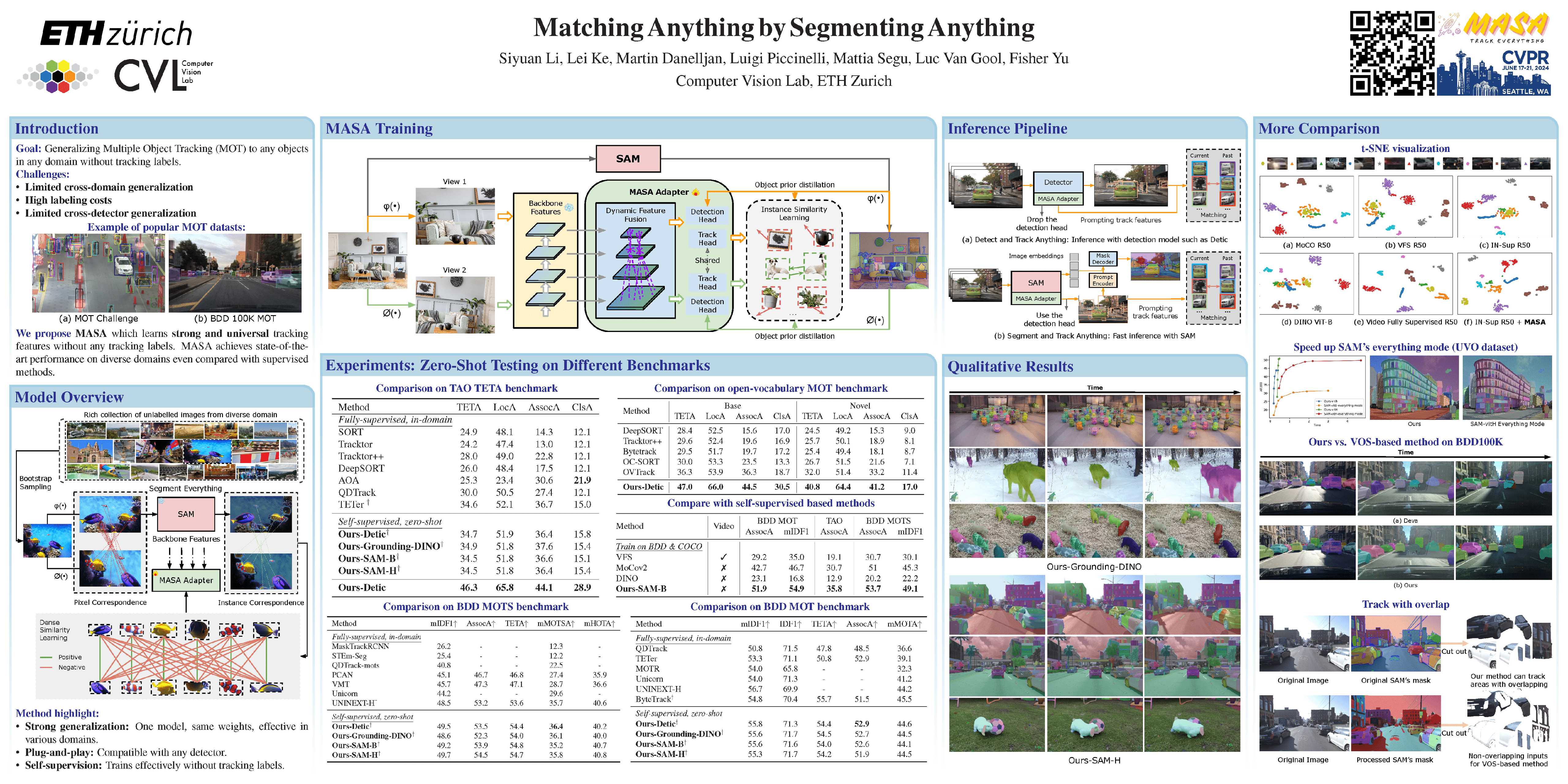 🔥 Matching Anything by Segmenting Anything
🔥 Matching Anything by Segmenting Anything
Siyuan Li, Lei Ke, Martin Danelljan, Luigi Piccinelli, Mattia Segu, Luc Van Gool, Fisher Yu
[paper] [code] [video]
Topic: Video: Low-level analysis, motion, and tracking
Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #421
 DiffMOT: A Real-time Diffusion-based Multiple Object Tracker with Non-linear Prediction
DiffMOT: A Real-time Diffusion-based Multiple Object Tracker with Non-linear Prediction
Weiyi Lv, Yuhang Huang, Ning Zhang, Ruei-Sung Lin, Mei Han, Dan Zeng
[paper] [code]
Topic: Video: Low-level analysis, motion, and tracking
Session: Thu 20 Jun 8 p.m. EDT — 9:30 p.m. EDT #455
 Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, Jiaqi Wang
[paper] [code] [video] [demo]
Topic: Vision, language, and reasoning
Session: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #327
🔥 Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, Saining Xie
[paper] [code]
Topic: Vision, language, and reasoning
Session: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #390
 🔥 LISA: Reasoning Segmentation via Large Language Model
🔥 LISA: Reasoning Segmentation via Large Language Model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, Jiaya Jia
[paper] [code] [demo]
Topic: Vision, language, and reasoning
Session: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #413
 ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
Mu Cai, Haotian Liu, Dennis Park, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Yong Jae Lee
[paper] [code] [video] [demo]
Topic: Vision, language, and reasoning
Session: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #317
 🔥 MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
🔥 MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, Wenhu Chen
[paper]
Topic: Vision, language, and reasoning
Session: Thu 20 Jun 1:30 p.m. EDT — 3 p.m. EDT #382
We would love your help in making this repository even better! If you know of an amazing paper that isn't listed here, or if you have any suggestions for improvement, feel free to open an issue or submit a pull request.