This project implements a scalable real-time processing and analyzing tool for twitter, it streams live tweets fro twitter, analyze them based on the message content of the tweet and determine the tweet topic using some already defined keywords, and eventually visualize the results in real-time.
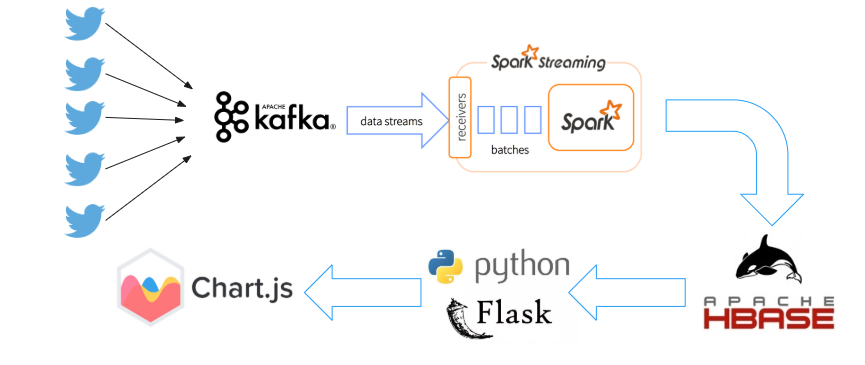
The diagram below shows the technologies that have been used for this project:

The design architecture for the project is as shown:
First you need to make sure that you properly set up the environment, for me I used Cloudera and installed Kafka and included Cloudera's PySpark to my coding environment.
Open hbase-shell and create a schema using create 'tweets_details', 'tweets_info'
The next step is to run the Kafka server using the command:
$KAFKA_HOME/bin/kafka-server-start.sh /usr/lib/kafka_2.11-2.1.0/config/server.properties
Update the values of access token and then run twitter_reader.py script to read the tweets and produce them using Kafka Producer.
Run twitter_spark.py script to read from Kafka and process the messages
Run visualize.py script to access the page that visualizes the data using Charts.js
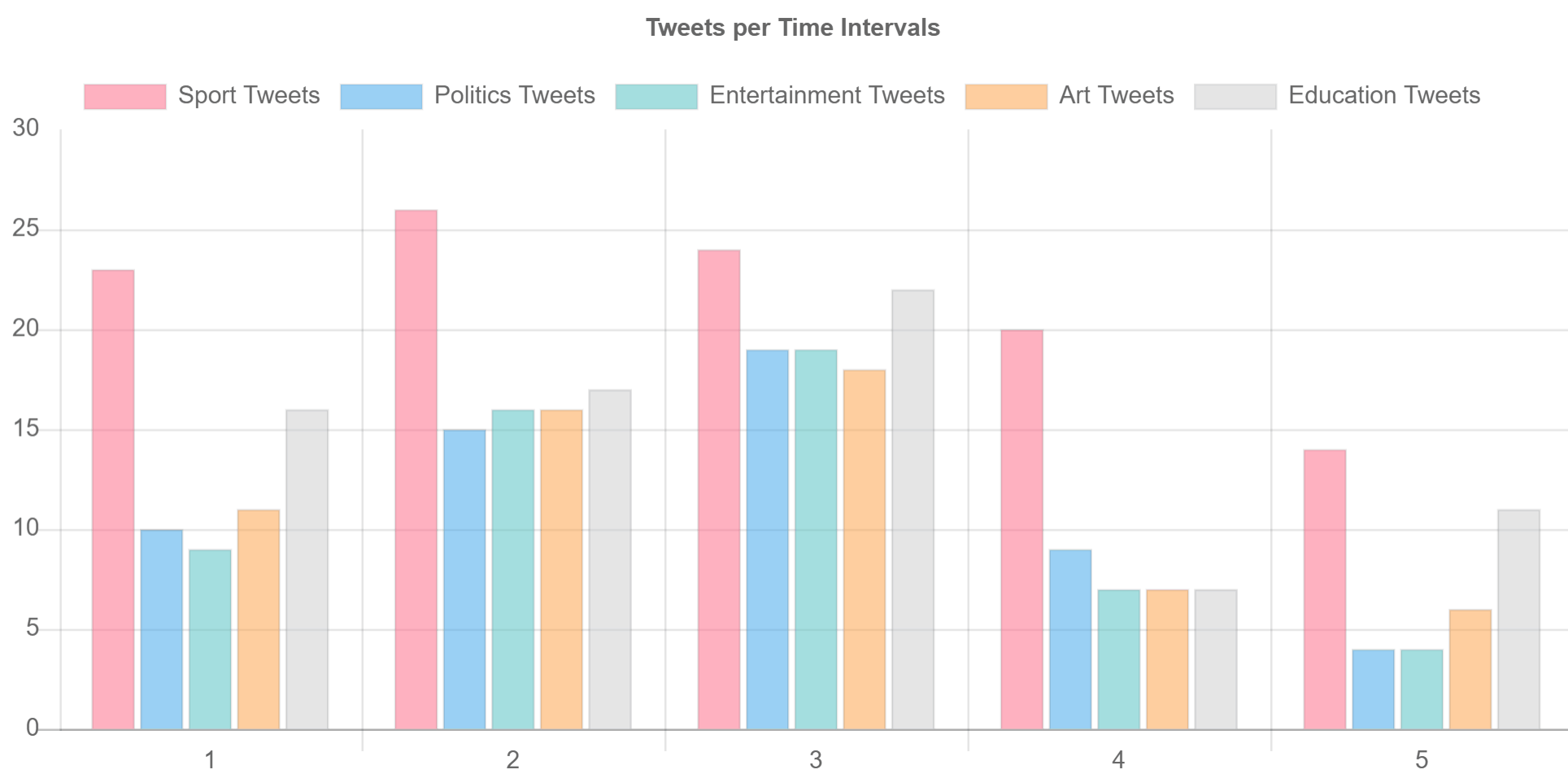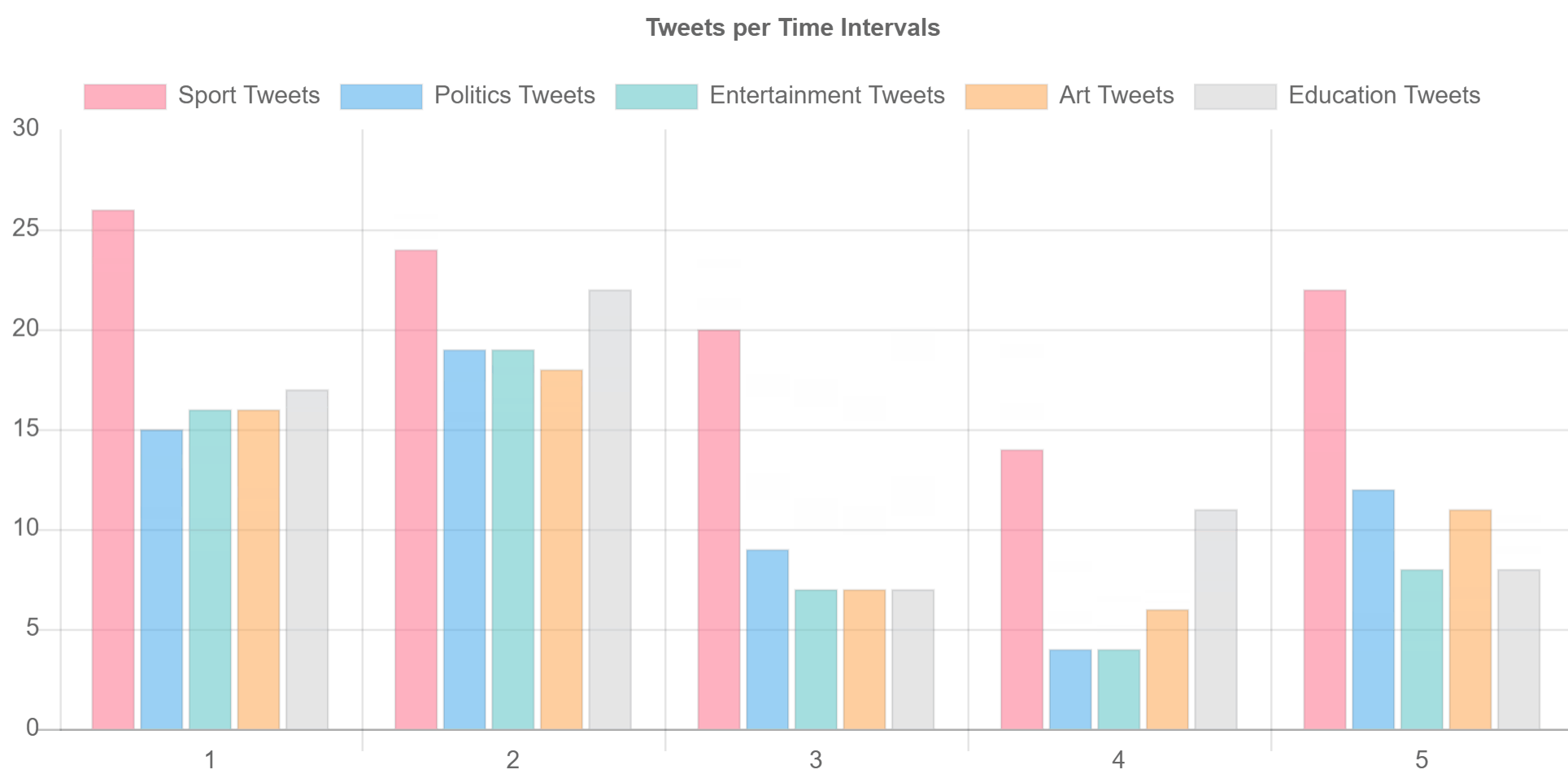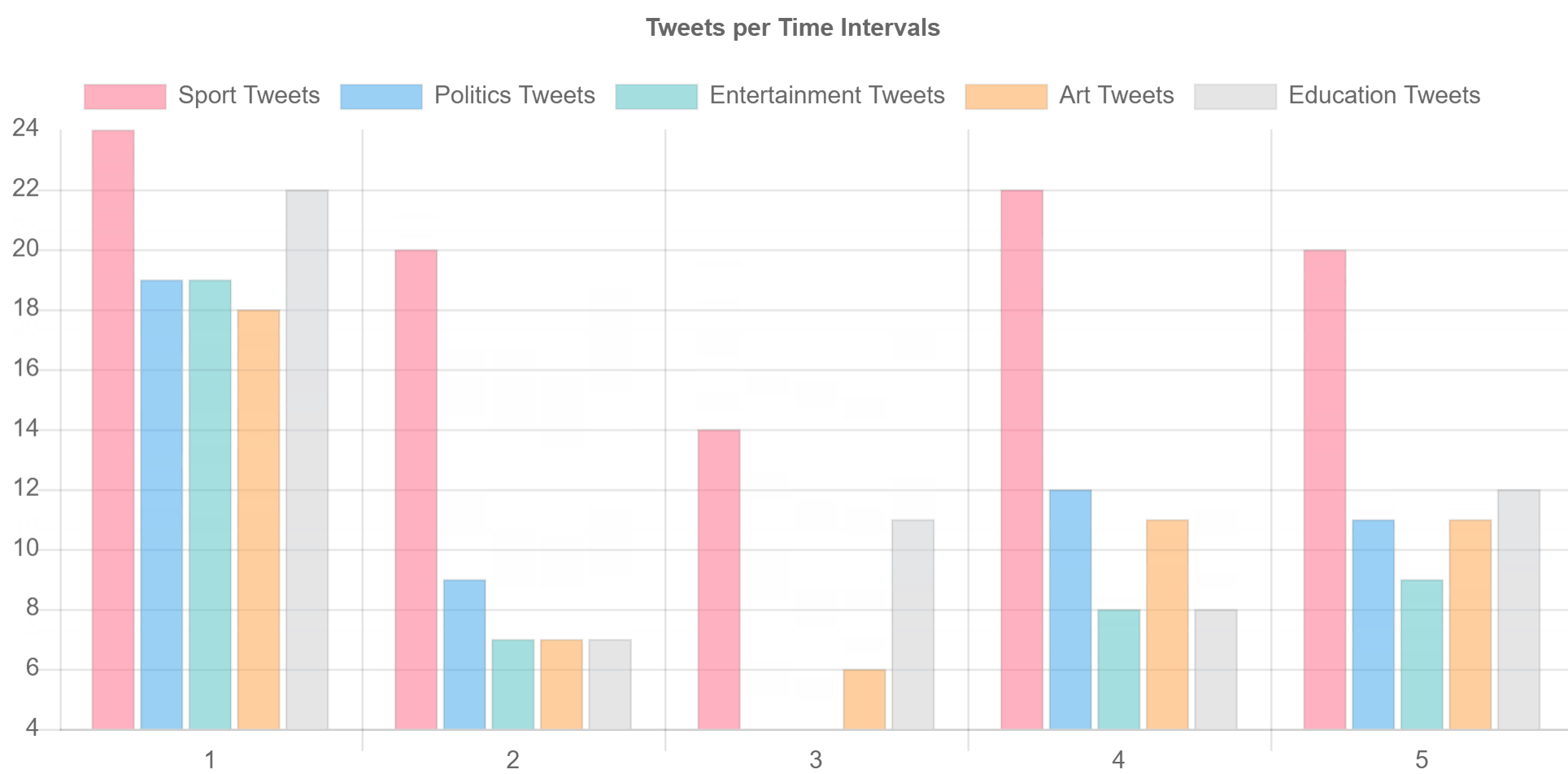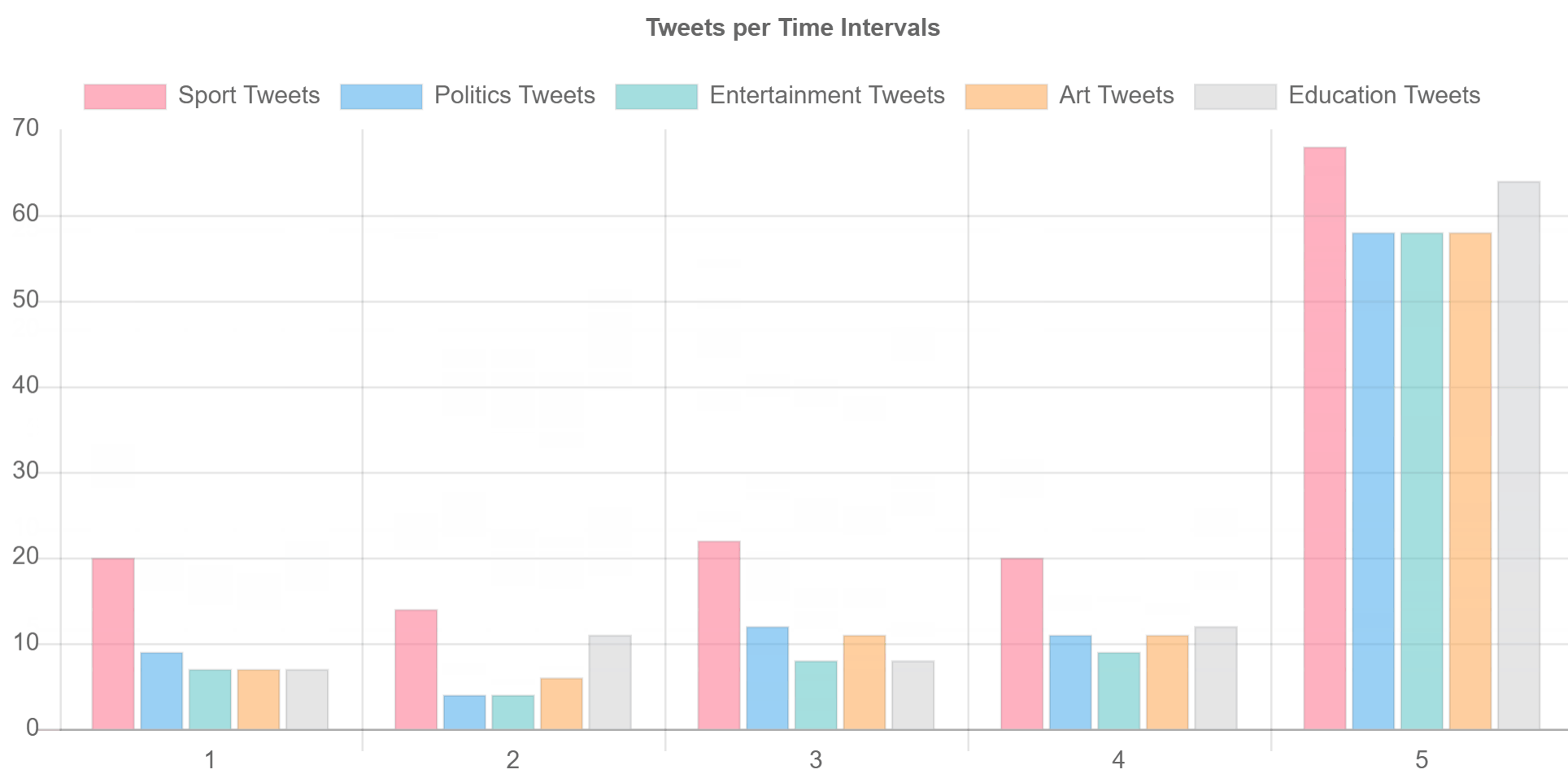
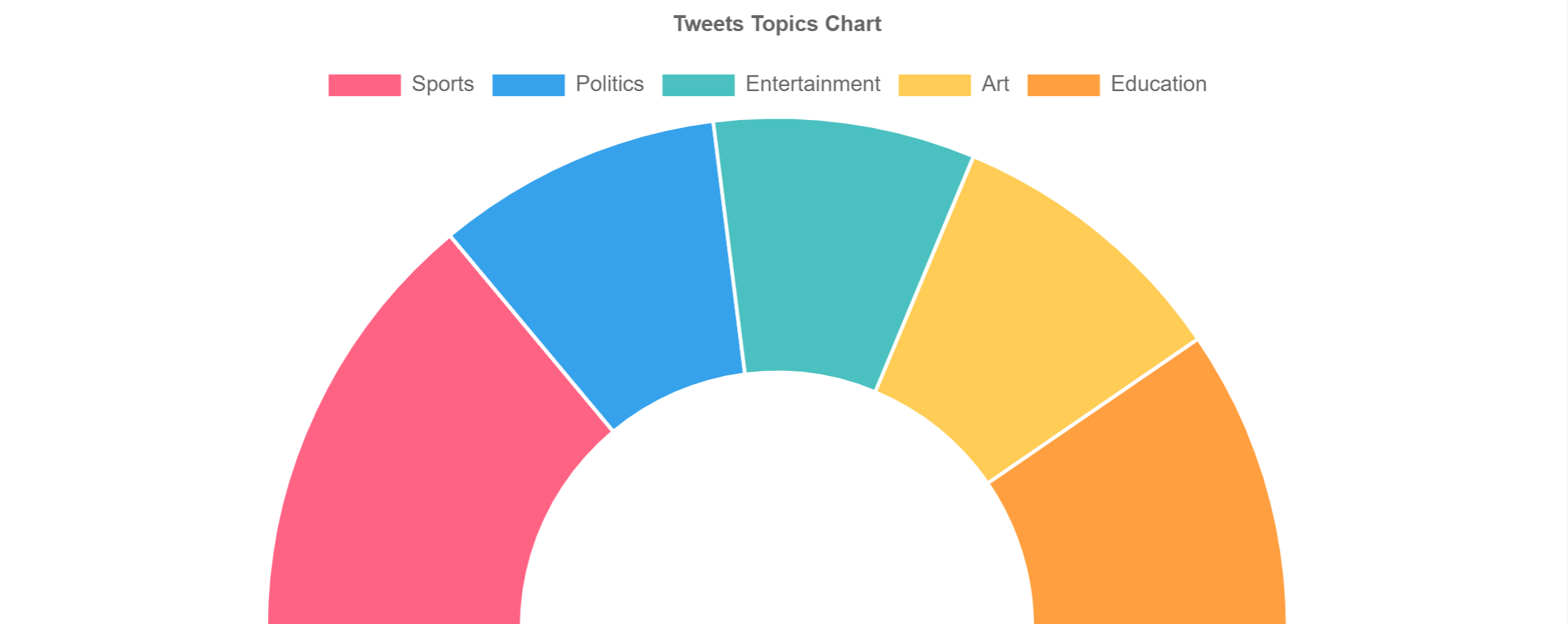
you should be able to see two real-time graphs one is bar chart to show and split data per time intervals (5 seconds in code) and the other shows a pie chart for all data collected within a defined amount of time (3 minutes in the code)