This repository provides an end-to-end pipeline for detecting deepfake images using facial features extracted via MediaPipe and classifying them with advanced machine learning models like XGBoost, Random Forest, and an ensemble Voting Classifier.
- Project Overview
- Features Extracted
- Dataset
- Model Pipeline
- Installation
- Usage
- Results
- Acknowledgments
Deepfakes pose significant challenges in today's digital world, from misinformation to security risks. This project leverages MediaPipe Face Mesh for extracting facial landmarks and geometric features, which are then used to classify images as real or fake using machine learning algorithms.
- Facial landmark detection with MediaPipe.
- Extraction of geometric features (eye opening, mouth opening, etc.).
- Machine learning-based classification with models such as XGBoost and Random Forest.
- Comprehensive visualization of results, including confusion matrices and ROC curves.
The pipeline extracts the following features from images:
- 3D Facial Landmark Coordinates: Flattened vector of
x,y, andzcoordinates for all detected facial landmarks. - Geometric Features:
- Left and right eye opening distances.
- Mouth opening distance.
These features help detect inconsistencies in fake images created by GAN-based systems.
The project uses the 140k Real and Fake Faces dataset from Kaggle. The dataset consists of real and fake images divided into train, valid, and test splits.
-
Feature Extraction:
- Images are resized to
224x224and processed with MediaPipe. - Geometric and landmark features are extracted.
- Images are resized to
-
Preprocessing:
- Features are scaled using
StandardScaler.
- Features are scaled using
-
Model Training:
- Individual classifiers:
XGBoostandRandom Forest. - Ensemble Voting Classifier with soft voting.
- Individual classifiers:
-
Evaluation:
- Metrics: Accuracy, ROC AUC, Confusion Matrix, Classification Report.
- Visualizations: Confusion Matrix and ROC Curve.
Ensure you have Python 3.9+ installed along with the following packages:
pip install numpy opencv-python mediapipe matplotlib seaborn tqdm joblib scikit-learn xgboostDownload the dataset and place it in the following structure:
real-vs-fake/
train/
real/
fake/
valid/
real/
fake/
test/
real/
fake/
Update the DATASET_PATH variable in the code with the correct path.
datasets = prepare_dataset(DATASET_PATH, max_samples=100)This function processes images, extracts features, and saves them as compressed .npz files.
results = train_models(datasets)This step trains and evaluates the models on the extracted features.
plot_results(results, datasets['test'][0], datasets['test'][1])Confusion matrices and ROC curves will be displayed.
with open('mediapipe_model.pkl', 'wb') as f:
pickle.dump({
'model': results['model'],
'scaler': results['scaler']
}, f)This saves the trained model and scaler for future inference.
- Accuracy:
0.8076 - ROC AUC:
0.8929
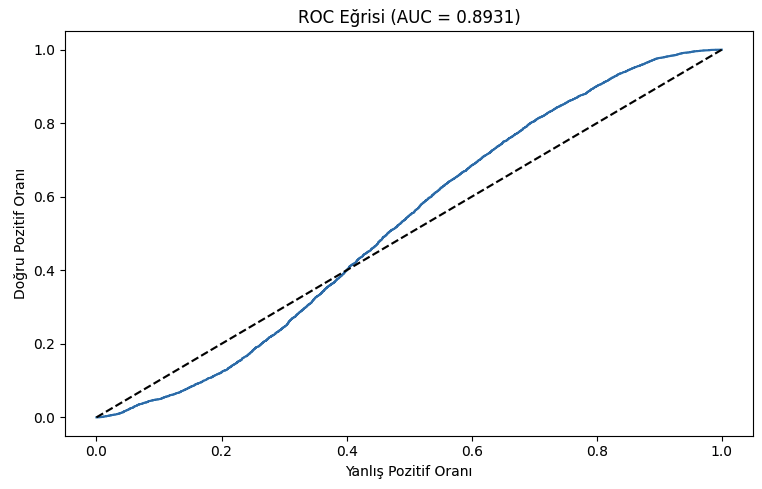
- Accuracy:
0.8094 - ROC AUC:
0.8931
| Predicted Real | Predicted Fake | |
|---|---|---|
| Actual Real | 7898 | 2100 |
| Actual Fake | 1700 | 8300 |
| Metric | Class 0 (Real) | Class 1 (Fake) | Macro Avg | Weighted Avg |
|---|---|---|---|---|
| Precision | 0.82 | 0.80 | 0.81 | 0.81 |
| Recall | 0.79 | 0.83 | 0.81 | 0.81 |
| F1-Score | 0.81 | 0.81 | 0.81 | 0.81 |
| Support | 9998 | 10000 | 19998 | 19998 |
Special thanks to: