Untuk proyek ini saya memilih domain Manajemen Perusahaan.
Ada satu perusahaan yang dikenal dengan ConDrossiers atau lebih singkatnya CoDros. CoDros adalah sebuah perusahaan di Indonesia yang bergerak di bidang data management, data integration, dan database systems yang tujuannya adalah untuk mempersiapkan infrastruktur manajemen. Selain itu, CoDros juga berperan untuk mendefinisikan sistem kerja perusahaan yang belum terdefinisi dengan baik agar proses bisnis perusahaan tersebut dapat beroperasi dengan baik.
Setelah menjalani bisnisnya selama kurang lebih 12 tahun, CoDros dihadapi dengan situasi pandemi COVID-19 pada tahun 2020. Seluruh pegawainya tidak dapat melakukan pekerjaannya dari kantor dan harus beradaptasi dengan budaya work from home. Akibatnya, terdapat dugaan bahwa perubahan sistem kerja yang besar ini mengakibatkan perubahan perilaku pegawainya, bahkan hingga meningkatkan turnover rate perusahaan. Kecenderungan employee resignation ini mengancam kapabilitas operasional perusahaan sehingga manajemen perlu mengambil tindakan. Dalam hal ini, agar proses bisnis tetap baik, perusahaan perlu melakukan manajemen terhadap karyawan. Melalui proyek ini, dilakukan analisis mengenai potensial karyawan.
Menurut penelitian disebutkan bahwa karyawan memiliki beberapa alasan untuk meninggalkan tempat kerja mereka, seperti stres kerja, kepuasan kerja, keamanan kerja, lingkungan kerja, motivasi, upah, dan penghargaan. Selanjutnya, pergantian karyawan memiliki dampak besar pada organisasi karena biaya yang terkait dengan pergantian karyawan dan dapat berdampak negatif pada produktivitas, keberlanjutan, daya saing, dan profitabilitas organisasi. Namun, organisasi harus memahami kebutuhan karyawannya, yang akan membantu organisasi, mengadopsi strategi tertentu untuk meningkatkan kinerja karyawan dan mengurangi pergantian. Dengan demikian, penerapan strategi akan meningkatkan kepuasan kerja, motivasi dan produktivitas individu dan organisasi, yang dapat mengurangi masalah ketenagakerjaan, ketidakhadiran, dan pergantian karyawan.
- Apa saja faktor yang mempengaruhi karyawan untuk melakukan resign?
- Apa faktor terbesar yang mempengaruhi karyawan untuk melakukan resign?
- Menganalisis karakteristik karyawan terhadap kinerja selama di perusahaan
- Mengetahui apakah mereka akan tetap bekerja di CoDros atau akan resign dalam waktu dekat
Dalam hal ini, saya mengajukan tiga pendekatan algoritma klasifikasi dalam Machine Learning, yaitu Logistic Regression, Decision Tree, dan Random Forest.
-
Logistic Regression.
Algoritma ini umumnya digunakan dalam model klasifikasi biner. LogRes adalah algoritma yang dapat digunakan untuk memodelkan peluang suatu kelas atau kejadian tertentu. Digunakan ketika data dapat dipisahkan secara linier dan hasilnya biner. Meski demikian, algoritma ini juga bisa digunakan dalam permasalahan klasifikasi multi-kelas. Kelebihannya yaitu algoritma bekerja cukup sederhana. Kekurangannya yaitu karena sederhana, untuk permasalahan yang kompleks algoritma ini kurang bisa diandalkan. -
Decision Tree
Decision Tree adalah struktur pohon seperti diagram alur di mana tiap satu kotak mewakili fitur (atau atribut), cabang mewakili aturan keputusan, dan setiap bagian daun mewakili hasilnya. Node paling atas dalam pohon keputusan dikenal sebagai root node. Root node belajar untuk mempartisi berdasarkan nilai atribut. Ini mempartisi pohon secara rekursif memanggil partisi rekursif. Struktur seperti diagram alur ini dapat memudahkan dalam pengambilan keputusan. Decision Tree bekerja dengan cara menyeleksi atribut terbaik berdasarkan penilaian seperti Information Gain lalu memisahkan atribut menjadi subset yang lebih kecil. Proses tersebut diulang secara rekursif untuk setiap subset sampai salah satu kondisi cocok. -
Random Forest
Merupakan Ensemble Learning yang terdiri dari beberapa macam algoritma. Random Forest adalah algoritma klasifikasi yang terdiri dari banyak pohon keputusan. Random Forest menambahkan suatu randomness tambahan pada model, sambil membuat suatu pohon keputusan. Alih-alih mencari fitur yang paling penting saat memisahkan sebuah node, RF mencari fitur terbaik di antara subset fitur yang acak. Hal ini menghasilkan keragaman yang luas yang umumnya menghasilkan model yang lebih baik. Salah satu kelebihan Random Forest adalah dapat digunakan untuk masalah klasifikasi dan regresi dengan hasil yang baik.
Dataset yang digunakan merupakan data karyawan perusahaan ConDrossiers yang diambil dari Kaggle.
Variabel-variabel pada Karakteristik Karyawan ConDrossiers adalah sebagai berikut:
- employee_id : merupakan nomor unik penanda karyawan
- umur : merupakan umur karyawan
- jenis_kelamin : merupakan jenis kelamin karyawan
- IPK : merupakan Indeks Prestasi Kumulatif karyawan ketika lulus kuliah
- level : merupakan jabatan yang dimiliki karyawan di perusahaan
- tahun_lulus : merupakan tahun lulus karyawan dari pendidikan tinggi/universitas
- status_perkawinan : merupakan status perkawinan karyawan
- divisi : merupakan divisi tempat karyawan bekerja
- rerata_jam_bulanan : merupakan nilai rata-rata karyawan bekerja per bulannya
- tingkat_kepuasan_bekerja : merupakan nilai kepuasan yang dimiliki karyawan terhadap perusahaan tempat bekerja
- nilai_evaluasi_terakhir : merupakan nilai karyawan selama bekerja dalam periode terakhir
- jumlah_proyek_yang_dikerjakan : merupakan jumlah pekerjaan yang diselesaikan karyawan
- lama_di_perusahaan : merupakan durasi karyawan bekerja di perusahaan
- kecelakaan_kerja : merupakan kasus kecelakaan yang pernah dialami karyawan
- promosi_5thn_lalu : merupakan status karyawan yang mendapat hadiah dari perusahaan melalui promosi
- tingkat_gaji : merupakan tingkat gaji yang dimiliki karyawan
- resign : merupakan keputusan karyawan untuk bertahan atau resign
Data Preparation yang digunakan yaitu:
- Deteksi Missing Value
Dataset memiliki Missing Value pada beberapa fiturnya, sehingga jika dibiarkan kosong tidak terisi maka akan menyebabkan model tidak menghasilkan model yang diharapkan. Seperti akan terjadi error. Sehingga untuk kasus dalam proyek ini fitur yang memiliki Missing Value perlu diisi dengan nilai tertentu. Salah satu cara yaitu dengan melakukan imputasi nilai rata-rata dari fitur kemudian mengisinya pada nilai yang kosong - Deteksi Outlier
Beberapa pengamatan dalam satu set data kadang berada di luar lingkungan pengamatan data lainnya. Pengamatan seperti itu disebut outlier. Untuk itu, dilakukan visualisasi data berupa boxplot untuk mengetahui rentang data yang termasuk outlier. Nilai yang termasuk outlier terdapat pada luaran Q1 dan Q3. Lalu, untuk mengatasinya digunakan metode IQR yang memiliki konsep kuartil. - Analisis Univariat
Bagian ini dilakukan untuk melihat sebaran setiap fitur, bagi jenis kategorik dan jenis numerik. Sebaran ini dilihat untuk memberikan gambaran data, merangkum data dalam bentuk distribusi visual dan menemukan pola dalam data. - Analisis Multivariat
Analisis Multivariate menunjukkan hubungan antara dua atau lebih variabel pada data. Analisis Multivariate menunjukkan hubungan antara dua variabel biasa disebut sebagai bivariat.
Bagian ini dilakukan untuk melihat hubungan antar variabel yang ditunjukkan dalam peta hubungan korelasi. Nilai yang mendekati angka 1 memberikan tanda bahwa hubungan variabel berkorelasi positif. - Drop fitur
Dilakukan penghapusan terhadap fitur yang berpengaruh kecil pada pemodelan, seperti fitur employee_id, fitur umur, fitur tahun_lulus, dan fitur IPK, karena fitur tersebut tidak berhubungan secara langsung terhadap Label. - Encoding fitur kategorikal
Dilakukan agar fitur kategorik dapat diproses dalam model Machine Learning. Untuk melakukan proses encoding fitur kategori, salah satu teknik yang umum dilakukan adalah teknik one-hot-encoding. Teknik ini yaitu mengubah item dalam kolom jenis kategorikal menjadi numerik.
Pada tahap ini, saya mengembangkan model machine learning dengan tiga algoritma. Kemudian, membuat Classification report model masing-masing algoritma dan menentukan melihat algoritma yang memberikan skor akurasi terbaik. Algoritma yang akan digunakan, antara lain:
- Logistic Regression
- Decision Tree
- Random Forest
Dari pemodelan yang dilakukan untuk dua algoritma tersebut, didapatkan masing-masing metrik Classification report model yaitu sebagai berikut
Untuk Logistic Regression:
| precision | recall | f1-score | |
|---|---|---|---|
| 0 | 0.83109 | 0.92696 | 0.87641 |
| 1 | 0.59470 | 0.36259 | 0.45050 |
| accuracy | 0.79821 | ||
| macro avg | 0.71289 | 0.64477 | 0.66346 |
| weighted avg | 0.77716 | 0.79821 | 0.77925 |
Lebih lengkap untuk metrik evaluasi model Logistic Regression sebagai berikut

Untuk Decision Tree:
| precision | recall | f1-score | |
|---|---|---|---|
| 0 | 0.97603 | 0.97270 | 0.97436 |
| 1 | 0.90868 | 0.91917 | 0.91389 |
| accuracy | 0.96048 | ||
| macro avg | 0.94235 | 0.94593 | 0.94413 |
| weighted avg | 0.96066 | 0.96048 | 0.96056 |
Lebih lengkap untuk metrik evaluasi model Decision Tree sebagai berikut

Untuk Random Forest:
| precision | recall | f1-score | |
|---|---|---|---|
| 0 | 0.97579 | 0.99044 | 0.98306 |
| 1 | 0.96594 | 0.91686 | 0.94076 |
| accuracy | 0.97366 | ||
| macro avg | 0.97086 | 0.95365 | 0.96191 |
| weighted avg | 0.97354 | 0.97366 | 0.97341 |
Lebih lengkap untuk metrik evaluasi model Random Forest sebagai berikut

Berdasarkan kerja dari ketiga model yang digunakan, mengacu pada nilai akurasi yang didapatkan, disimpulkan bahwa model terbaik yaitu menggunakan algoritma Random Forest. Pada Random Forest, terdapat parameter random_state, parameter ini membuat solusi mudah untuk direplikasi. Nilai dari random_state selalu menghasilkan hasil yang sama jika diberikan dengan parameter dan data pelatihan yang sama. Beberapa sumber menyebutkan, semua parameter yang digunakan dalam model dapat terkadang berkinerja lebih baik daripada keadaan acak individu.
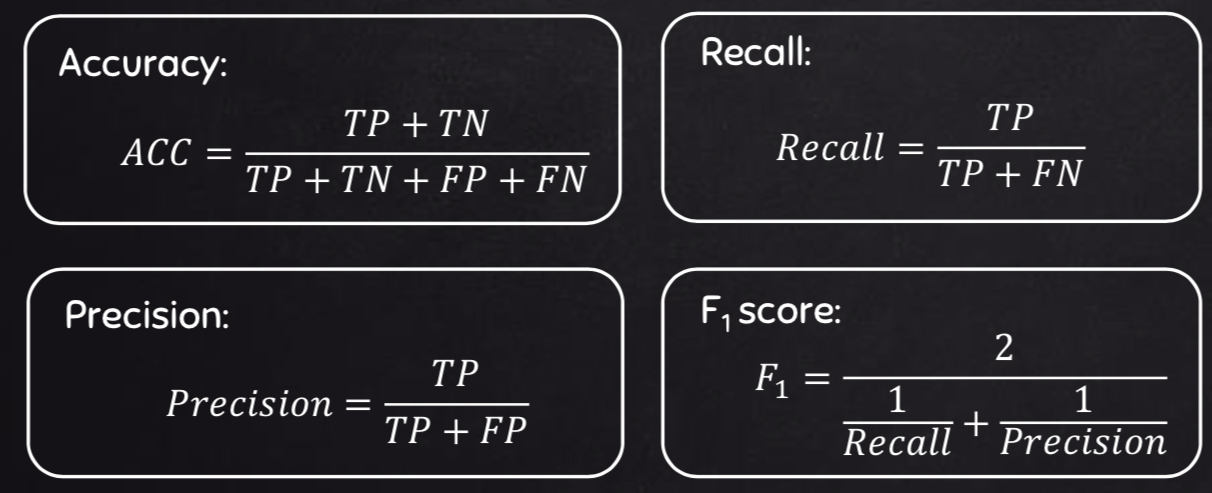
Dalam pengembangan model kasus ini, yaitu klasifikasi, digunakan metrik berupa akurasi, precision, recall, dan F1 score. Masing-masing yaitu sebagai berikut
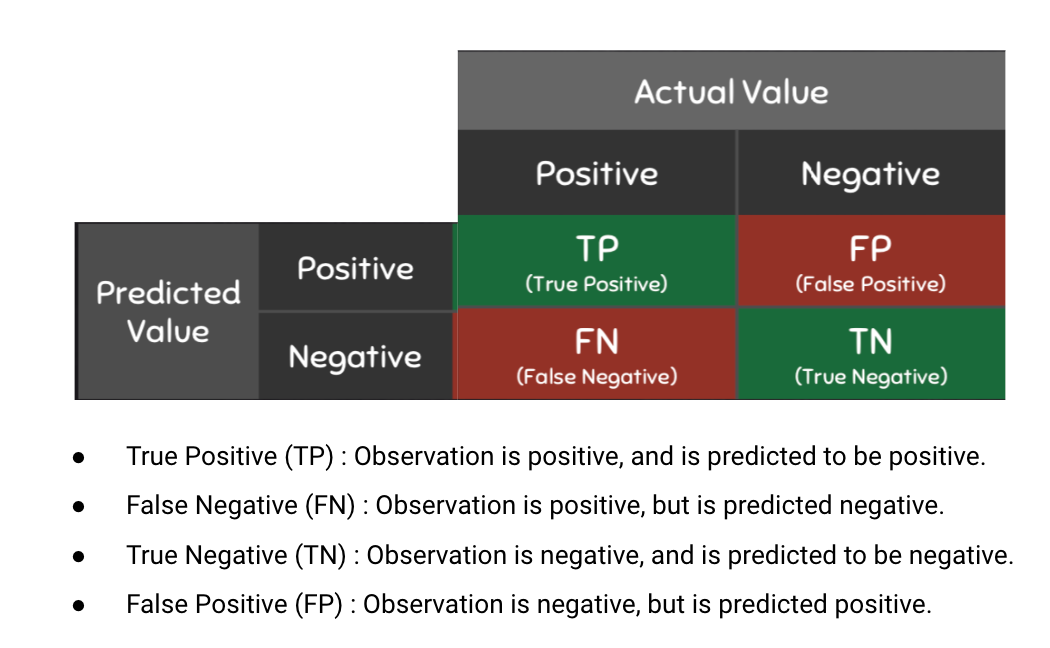
- Akurasi
Merupakan salah satu metrik yang memberikan perbandingan dari prediksi model yang benar terhadap semua kemungkinan prediksi model.
Akurasi = Jumlah prediksi yang benar/Total prediksifrom sklearn.metrics import accuracy_score accuracy_score(y_actual,y_predicted) - Precision
Merupakan rasio True Positive dengan semua nilai positif yang diprediksi oleh model.
Precision = True Positive/(True Positive + False Positive)
- Recall
Merupakan rasio True Positive dengan semua nilai positif yang ada di dataset Recall = TP/(TP + FN)
- F1 Score
Merupakan gabungan dari Precision dan Recall.
F-Score = 2 * (Precision * Recall)/(Precision + Recall)
F1-Score memiliki nilai antara 0 dan 1. Skor mendekati 1, model semakin baik.


Adapun kelebihan dan kekurangan dari penggunaan metrik accuracy, precision, recall, dan f1-score, yaitu. Kelebihan:
- Penggunaan metrik cukup banyak dalam setiap masalah klasifikasi biner
- Dapat dengan mudah dijelaskan kepada pemangku kepentingan bisnis.
- Lebih sedikit kompleksitas dan lebih sedikit sumber daya komputasi
- Dalam beberapa kasus, penggunaan f1-score dapat lebih baik digunakan saat distribusi kelas yang terdapat pada dataset tidaklah merata.
Kekurangan:
- Permasalahan yang menjadi kekurangan untuk metrik ini, dapat adanya masalah yang berbeda untuk kemungkinan kekeliruan dalam klasifikasi.
- Terkadang, evaluasi accuracy dapat digunakan hanya saat data yang dimiliki memiliki porsi yang seimbang antara False Positive dan False Negative
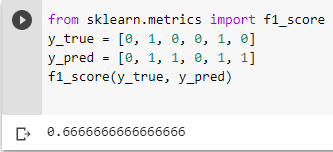
Lalu, untuk implementasi metrik accuracy, precision, recall, dan f1-score terhadap suatu model yang digunakan, dapat dengan kode berikut
print(metrics.classification_report(y_test, preds))
---Selesai---
Terima kasih