In this topic, we will make a database integration between mongoDB and postgreSQL. To do this, we will use two kafka connectors, a source connector from mongoDB and a sink connector at postgreSQL.
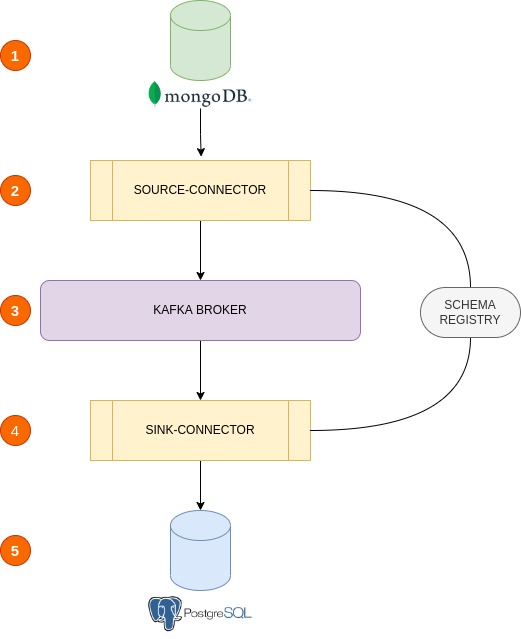
That guy will be the trigger of the flow.
That will be the "handler of mongoDB", that means it is still looking at mongoDB using mainly the (pipeline, schema.key, schema.value and topic.namespace.map) parameters as a guide.
- pipeline - what to look out for and how to treat.
- schema.key - the identification of the contract scheme.
- schema.value - the description of the contract scheme.
- topic.namespace.map - map of mongoDB collection to kafka topic.
obviously there are several other parameters, but I highlighted some
The kafka broker is the message manager, and that's fine. But you need to pay attention to schema-register, this guy will be the schema contract manager, he must save the (schema.key and schema.value) to be used in message formatting.
That will be the "handler to postgreSQL", that means it is still looking at kafka topic (mapped at topic.namespace.map on source connector) to make the jdbc insertions. Pay more attention at this parameters:
- topics - should be matched with
topic.namespace.mapand will become the table name. - pk.fields - the PK of table (should be at
pipelineon source connector). - fields.whitelist - should be contains the entire schema field that we want to save.
obviously there are several other parameters, but I highlighted some
That will be that "end" of us integration flow.
- docker
- docker compose
docker-compose build --no-cache && docker-compose up -d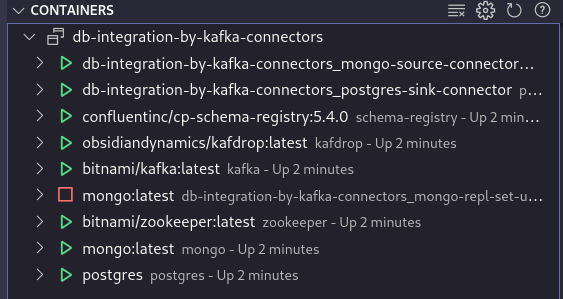
it's normal have um mongoDB container stopped (he's only used to generate a fake mongoDB cluster set).
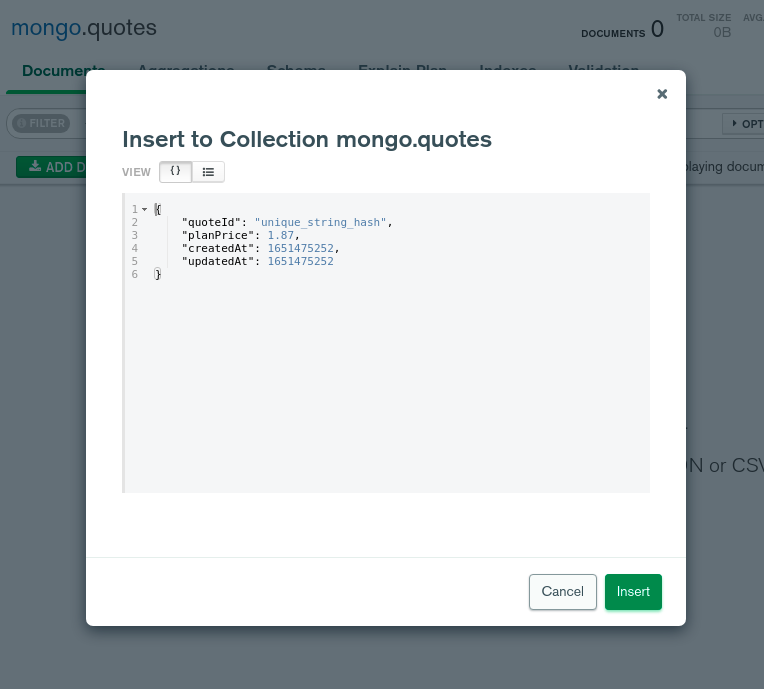
{
"quoteId": "unique_string_hash",
"planPrice": 1.87,
"createdAt": 1651475252,
"updatedAt": 1651475252
}
select * from "FROM_MONGO" fm;
That's it.
Have a nice experience!
:)