This projects implements LLama2 transformer decoder architecture for self-supervised prediction, which is at the core of LLMs. It aims to provide a simple and efficient implementation of popular Llama model which is based on the original transformer architecture which is highly flexible and powerful, but implements few upgrades such as: rotary embeddings, grouped query attention for a tradeoff between MHA and MQA, SwiGLU, RMS Norm and KV Caching.
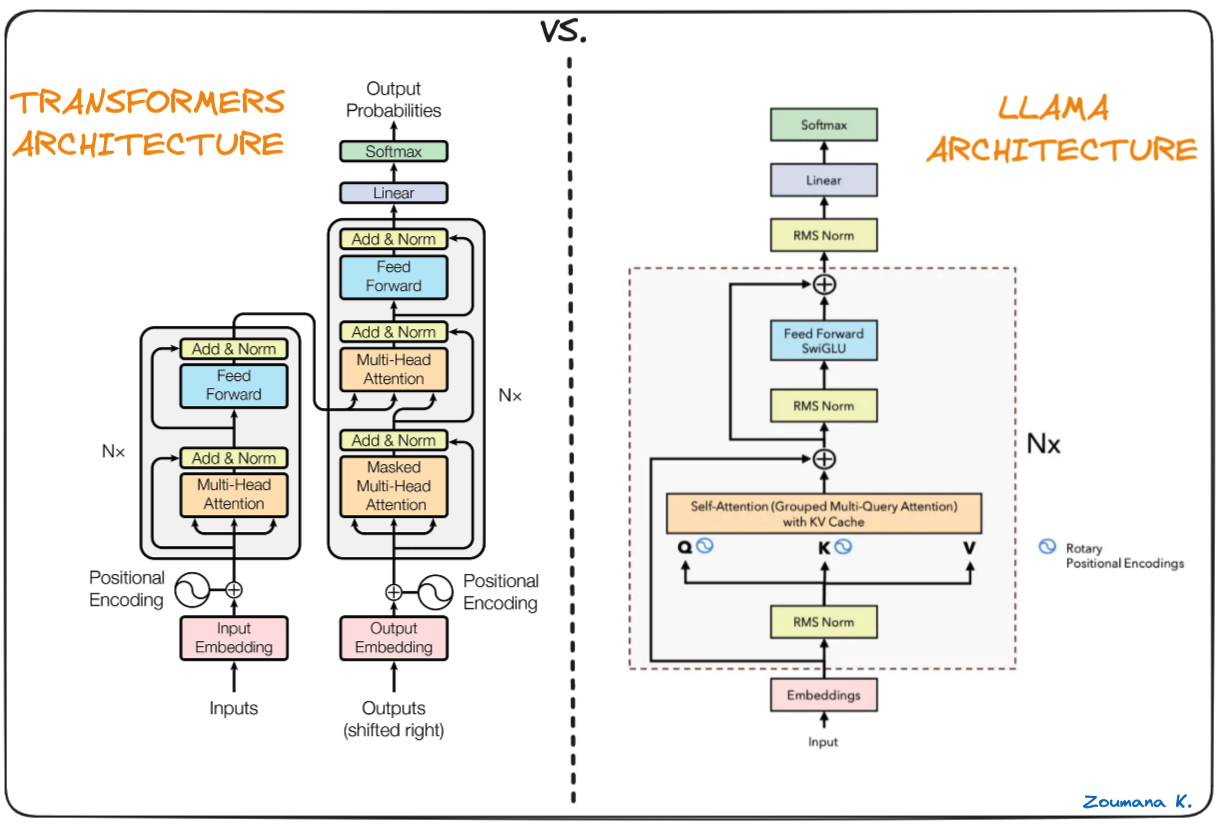
The Llama2 architecture consists of the Transformer Decoder architecture, coupled with few upgrades such as :
- Rotary Embeddings
- SwiGLU
- Grouped Query Attention
- KV Caching
Decoder: The decoder takes in the output of the encoder and generates the final output sequence. It also consists of a stack of decoder layers. Each decoder layer has a grouped query multi-head self-attention mechanism, feed-forward neural network. It benefits from RoPe encodings, KV caching and everything mentioned above.
Grouped Query Attention: The grouped query attention mechanism is a modification to the traditional attention mechanism in the transformer architecture. It allows the model to attend to different groups of queries within the input sequence, enabling a tradeoff between multi-head attention and multi-query attention. This helps improve the model's ability to capture complex dependencies and relationships within the data.
For more details on the transformer architecture, refer to the original paper: Llama.
🔀 Self-Supervised Prediction: The training loop is designed to support self-supervised prediction, enabling the model to learn from unlabeled data.
To get started with Transformer Plain, follow these steps:
-
Clone the repository:
git clone https://github.com/paulilioaica/Llama2-Pytorch cd Llama2-Pytorch/ -
Install the required dependencies:
pip install -r requirements.txt
from llama import LLama2
decoder_layers_num = 2
num_hidden = 16
num_heads = 4
num_kv_heads = 2
seq_len = 256
vocab_size = 100
model = Llama2(decoder_layers_num, num_hidden, num_heads, num_kv_heads, seq_len, vocab_size)
# batch_size, seq_len, 1 (vocab_index)
x = torch.randint(0, vocab_size, (1, seq_len))
output = model(x)
print(output.shape)torch.Size([1, 256, 100])
OR
-
Dataset: Make sure you have a dataset suitable for self-supervised prediction from Huggingface (or use the AG-NEWS one). Simply pass the
dataset_namefor training on your dataset of choice. -
Configure the training parameters: Adjust the hyperparameters by passing your own arguments.
-
Train the model: Run the training script to start the self-supervised prediction training loop.
-
Evaluate the model: Use the trained model to make predictions on your test dataset and evaluate its performance.
python main.py --num_layers 2 --n_heads 8 --num_kv_heads --seq_len 128 --num_hidden 128 --num_epochs 10 --batch_size 32 --lr 0.001 --device cpu --dataset_name ag_news
This project is licensed under the MIT License.