Tamil Emotional Speech Dataset is a collection of recordings in Sri Lankan Tamil, representing the distinct dialects spoken in the northern, eastern, western, and central provinces. It aims to capture the linguistic and emotional diversity of these regions for use in speech and emotion recognition research.

EmoTa is the first emotional speech dataset in Tamil, designed to reflect the linguistic diversity of Sri Lankan Tamil speakers. It includes 936 utterances from 22 native Tamil speakers (11 male, 11 female), each articulating 19 semantically neutral sentences across five primary emotions: Anger, Happiness, Sadness, Fear, and Neutrality.
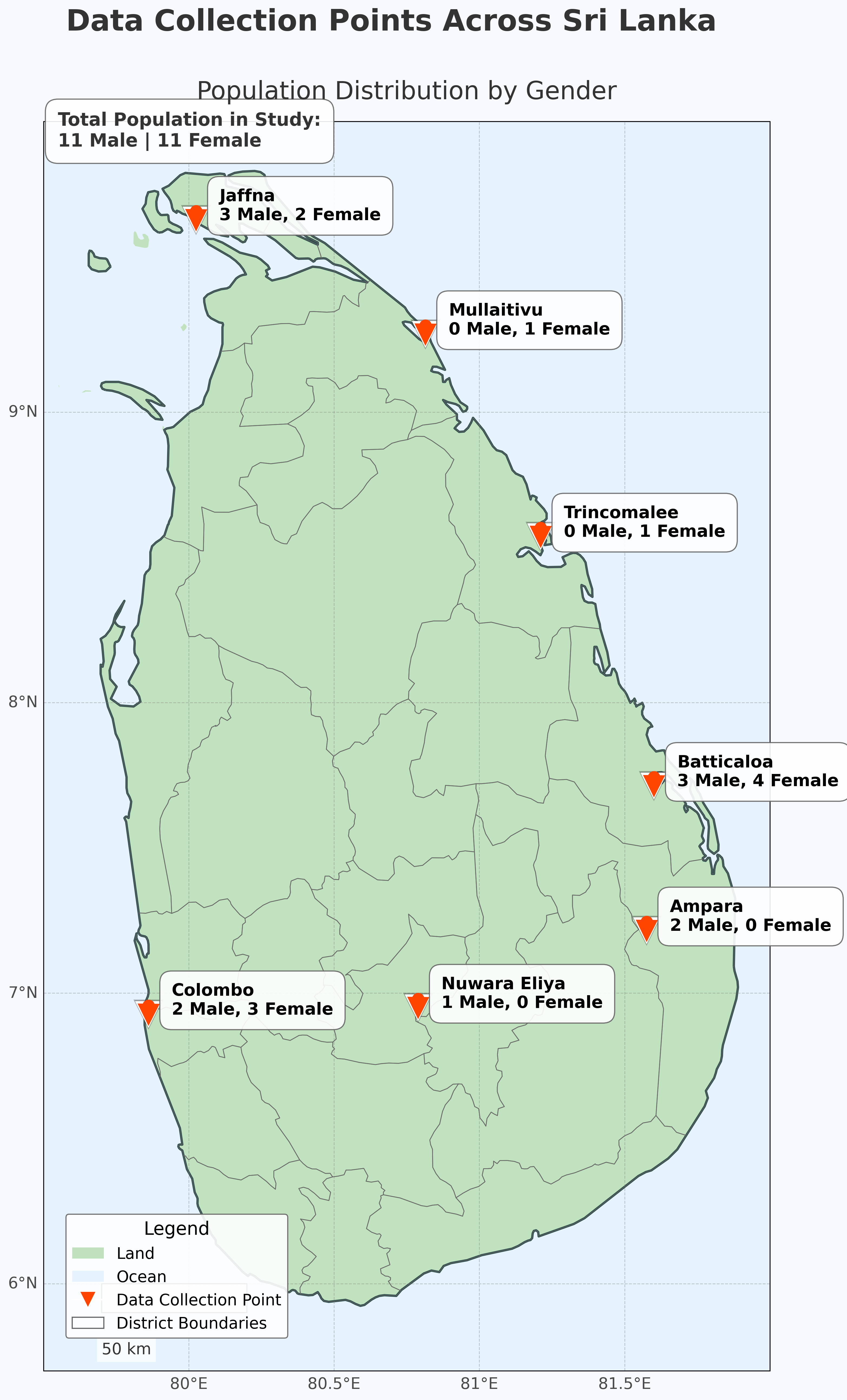
- Speakers: 22 native Tamil speakers (11 male, 11 female)
- Emotions: Anger, Happiness, Sadness, Fear, Neutrality
- Sentences: 19 semantically neutral sentences to reduce lexical bias
- Recording Quality: Captured in a controlled, soundproof environment with professional equipment
- Total Duration: Approx. 48 minutes of speech
The dataset is organized into emotion-based folders with the following naming convention:
EmoTa/
├── happy/
├── sad/
├── angry/
├── fear/
└── neutral/
└── <spkID>_<senID>_<emo[:3]>.wav
EmoTa aims to facilitate research in Speech Emotion Recognition (SER) for the Tamil language, offering a balanced and diverse representation of emotional expressions from native Tamil speakers. It is released as open-access to support further exploration of Tamil language processing.
| Name | ||
|---|---|---|
| Jubeerathan Thevakumar | jubeerathan.20@cse.mrt.ac.lk | here |
| Luxshan Thavarasa | luxshan.20@cse.mrt.ac.lk | here |
| Thanikan Sivatheepan | thanikan.20@cse.mrt.ac.lk | here |
| Uthayasanker Thayasivam* | rtuthaya@cse.mrt.ac.lk | here |